(Latest Revision: Mon Jun 03 2019)
[2019/06/03: added captions to figures]
[2019/05/30: inserted more figures]
[2019/03/21: format changes]
[2019/02/21: current 2019 updates]
Chapter Four -- Threads -- Lecture Notes
4.0 Objectives
Identify the basic components of a thread, and contrast threads and processes.
Describe the major benefits and significant challenges of designing
multithreaded processes.
Illustrate different approaches to implicit threading, including thread pools,
fork-join, and Grand Central Dispatch.
Describe how the Windows and Linux operating systems represent threads.
Design multithreaded applications using the Pthreads, Java, and Windows
threading APIs.
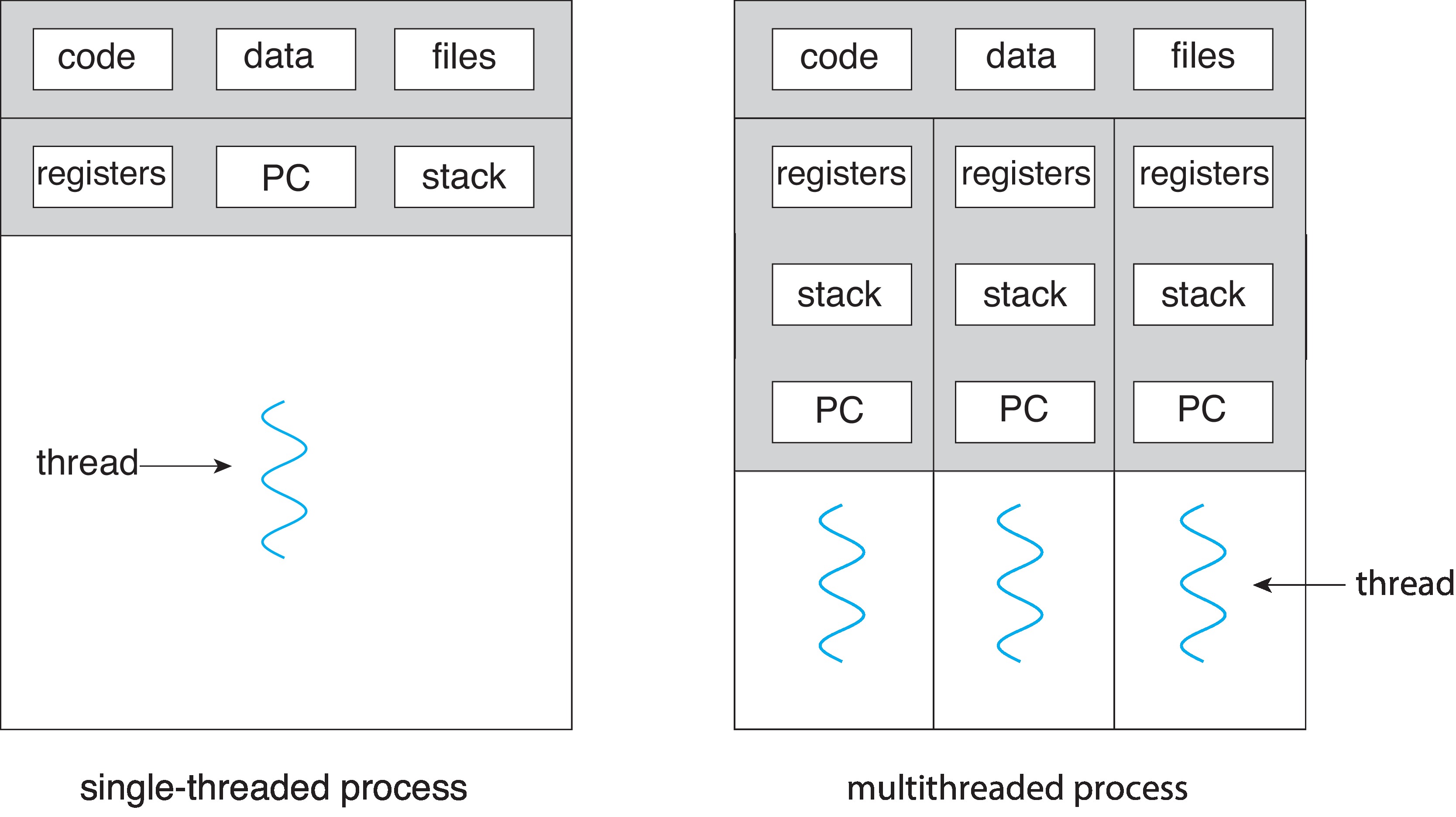
Figure 4.1: Single-threaded and multithreaded processes
4.1 Overview See figure 4.1 at right. We can think of a
thread as a part of a process that actually performs an execution
of the program - a sequence of instructions read from the program.
There is only one thread in a "traditional process" but there can
be multiple threads - multiple execution sequences - within
a single process. The threads can share many parts of the context
of the process, like the program code (aka the text),
variables and other data, open files, signals and other messages.
On the other hand, each thread is a separate execution sequence, and
so it needs NOT to share certain parts of its context. Each thread
needs to have its own separate program counter, CPU register values,
thread id number, and run-time stack for supporting its own function
calls.
4.1.1 Motivation It's common now that we need computer
applications to work for us on multiple separate concurrent
activities, such as a word processor that concurrently renders
a display, checks the spelling in a document, and reads
characters the user types with a keyboard.
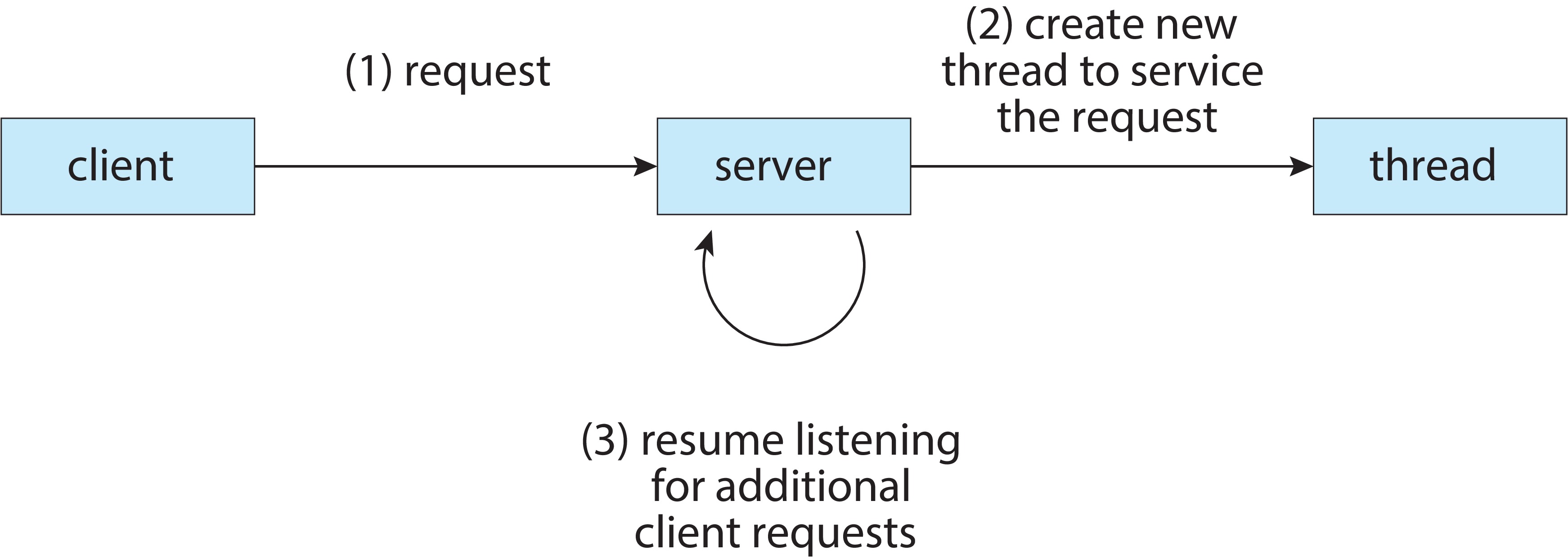
Figure 4.2: Multithreaded server architecture
When a multi-threaded process runs on a multiprocessor, it's possible
for two or more of the threads to execute simultaneously, which, of
course, can be a great efficiency win. One example would be a busy
Internet server process that can serve multiple clients simultaneously.
Most operating system kernels are multithreaded.
4.1.2 Benefits These are the main categories of benefits
of multithreaded programming.
Responsiveness: work is divided among threads and
some threads can continue working while others are blocked
(for example, waiting for I/O to complete) [ Note this is a type of
concurrent processing that applies to a uniprocessor ]
Resource Sharing: Unlike separate processes, threads can
share memory and other resources by default, which makes
it easier for them to communicate and cooperate. Also, there is
efficient utilization of primary memory when threads share
code and data .
Economy: Not much needs to be done to add a new thread
to an existing process, or to perform a context switch between two
threads of the same process. Therefore these operations usually
require less time and new memory allocation than creation of a new
process or a context switch between different processes.
Scalability: On a multiprocessor,
multiple threads can work on a problem in parallel
- truly simultaneously.
A single-threaded process can only run on one CPU at a time,
no matter how many CPUs are available in the computer.
4.2 Multicore Programming Threads or processes are
concurrent when they execute at approximately the
same time. This can happen on a computer with a single CPU (aka a
uniprocessor), when, for example, the operating system performs
multitasking. However, parallel threads or processes
truly execute simultaneously. This can only happen on a multiprocessor.
A definition: A multiprocessor with multiple computing cores (CPUs)
on a single chip is called a multicore system.
Figure 4.3: Concurrent execution on a single-core systemFigure 4.4: Parallel execution on a multicore system
4.2.1 Programming Challenges These are five challenges
in programming for multicore systems.
Identifying tasks: How do we divide up the work of a process
among the threads so that we get lots of work going on in
parallel?
Balance: There's a cost of adding a new thread to a process.
How do we make sure the new thread contributes enough to justify
that cost?
Data Splitting: In what ways do we need to divide up the
the data to allocate to separate threads?
Data Dependency: When thread X needs to get some data from
thread Y before thread X will be able to continue, how do we
synchronize actions of X and Y so the data is passed from one
to the other correctly?
Testing and debugging: The actions of two threads executing
in parallel can be interleaved in very numerous ways. Therefore
there can be a very large number of different orders of instruction
execution possible for a multithreaded application. How can we
effectively test and debug such applications that have unpredictable
execution paths?
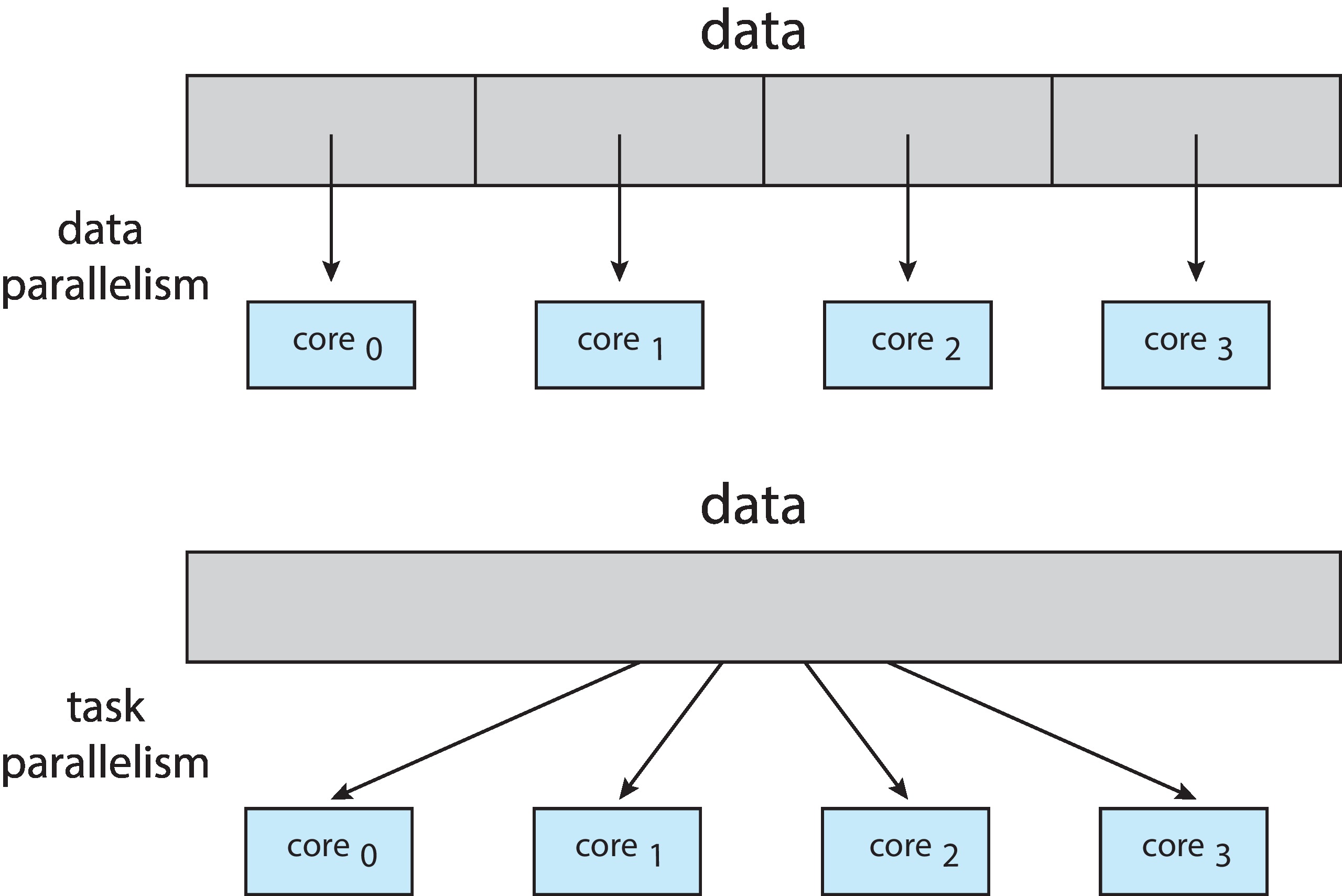
Figure 4.5: Data and task parallelism
4.2.2 Types of Parallelism There are two main kinds
of parallelism data parallelism and
task parallelism.
With data parallelism, the data is divided up, and each thread is
given one part of the data on which to work. Each thread does the same
operations, but on different data. If we have two lists to sort and
two threads, and if each thread sorts one of the lists, that's
data parallelism.
With task parallelism, the threads get different kinds of jobs to do,
and each thread uses whatever part(s) of the data it needs.
If one thread computes the average of an array while another thread
finds the maximum value in the array, that's task parallelism.
Programs often use some combination of the two strategies.
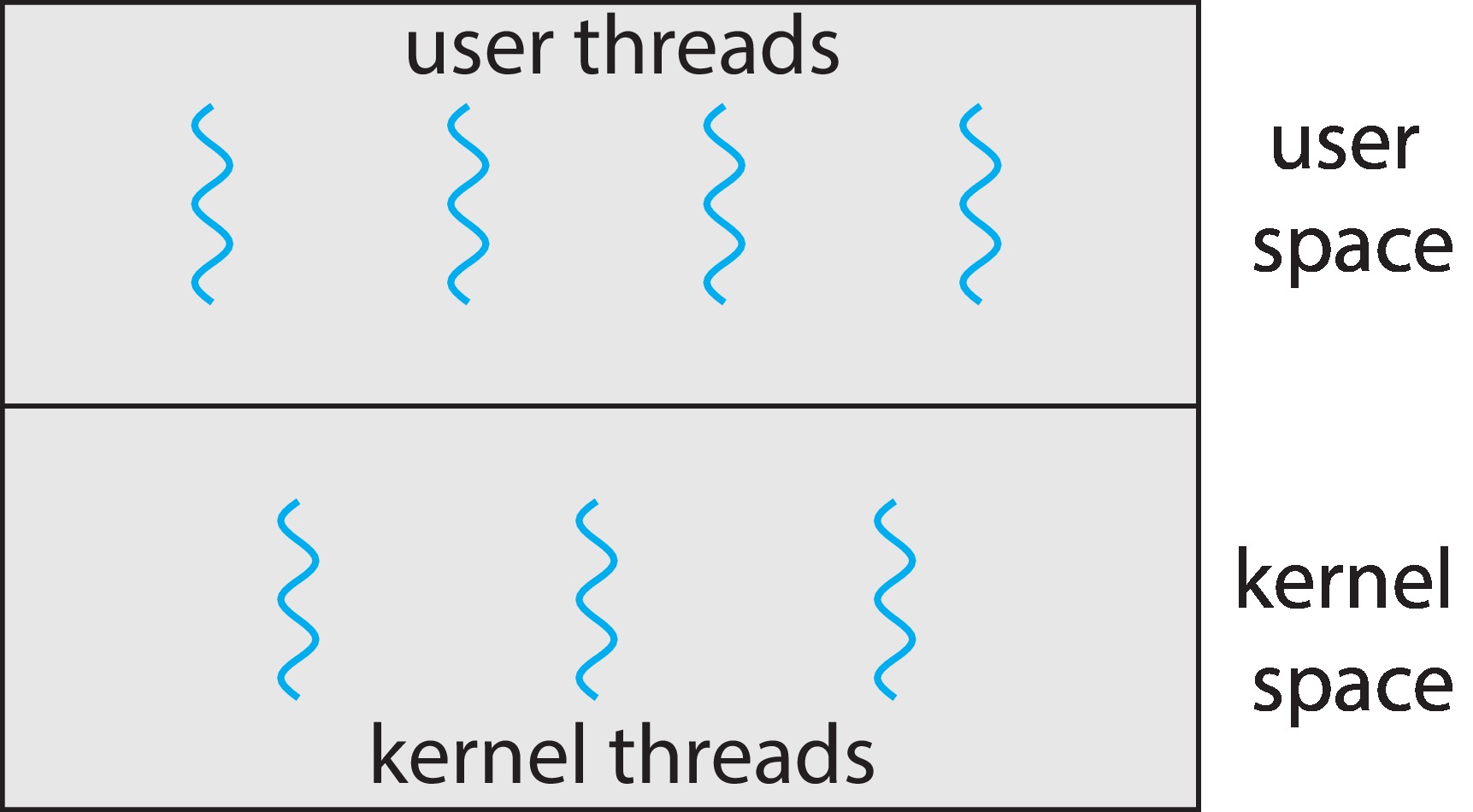
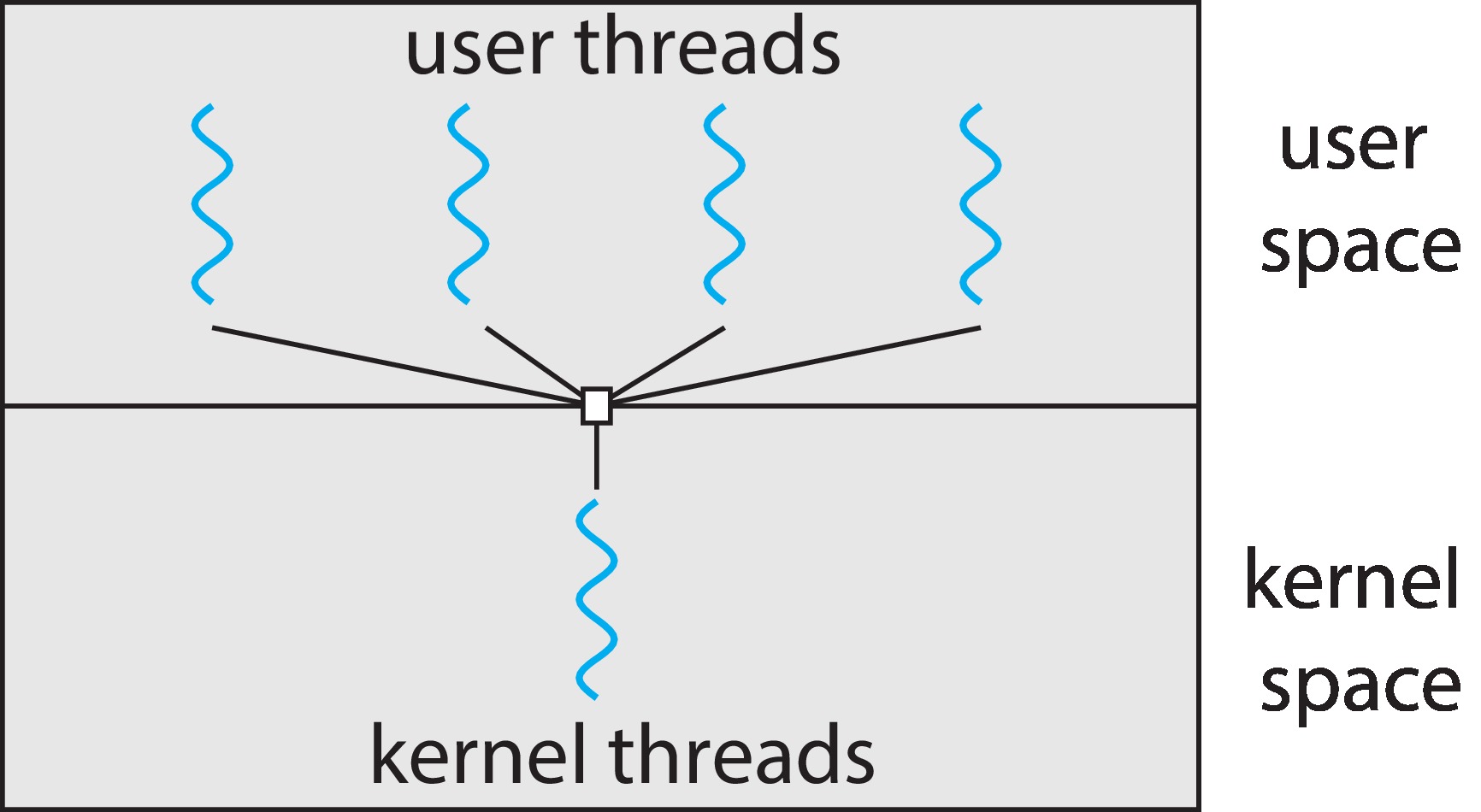
Figure 4.6: User and kernel threads
4.3 Multithreading Models
So far the threads we have studied are kernel-level
threads. There is also something called user-level
threads. Basically, user-level threads are
simulations of threads. User threads have some
nice advantages, but also some disadvantages.
Think about a single (kernel-level) thread that executes a time slice
in a CPU. Suppose we make that single thread execute software that
simulates multiple threads.
The resulting simulation can switch between multiple different
activities many times during the single time slice of the kernel-level
thread in the CPU. In other words, it can very quickly simulate multiple
context switches of multiple (simulated) threads, all during
one time slice of one kernel-level thread. That is a very nice
advantage - very low overhead for context switching.
Other advantages are that the simulator can quickly create, execute,
and terminate simulated threads at will without being slowed by
requesting help from the kernel and waiting for system calls to
execute.
Such simulated threads, user-level
threads, are quite popular for use
in many applications.
There has to be a correspondence between user- and kernel-level
threads. The mapping can be many-to-one, one-to-one, or
many-to-many.
Figure 4.7: Many-to-one model
4.3.1 Many-to-One Model:
In this model, a single kernel-level thread supports many user-level
threads. As explained above, context switching
is extremely fast among the user-level threads. This model
supports programmers that want to organize software as a group
of concurrent threads. However the kernel-level thread can only
execute in one CPU at a time. Therefore the user-level threads
can only execute one at a time. True parallelism
is not possible with this model. Also, if any of the user-level threads
makes a blocking system call, the kernel-level thread will have to block,
and so it will not be able to run code for any of the user-level
threads until it gets out of its wait queue.
The net effect is that all user threads are blocked if
any one of them makes a blocking system call.
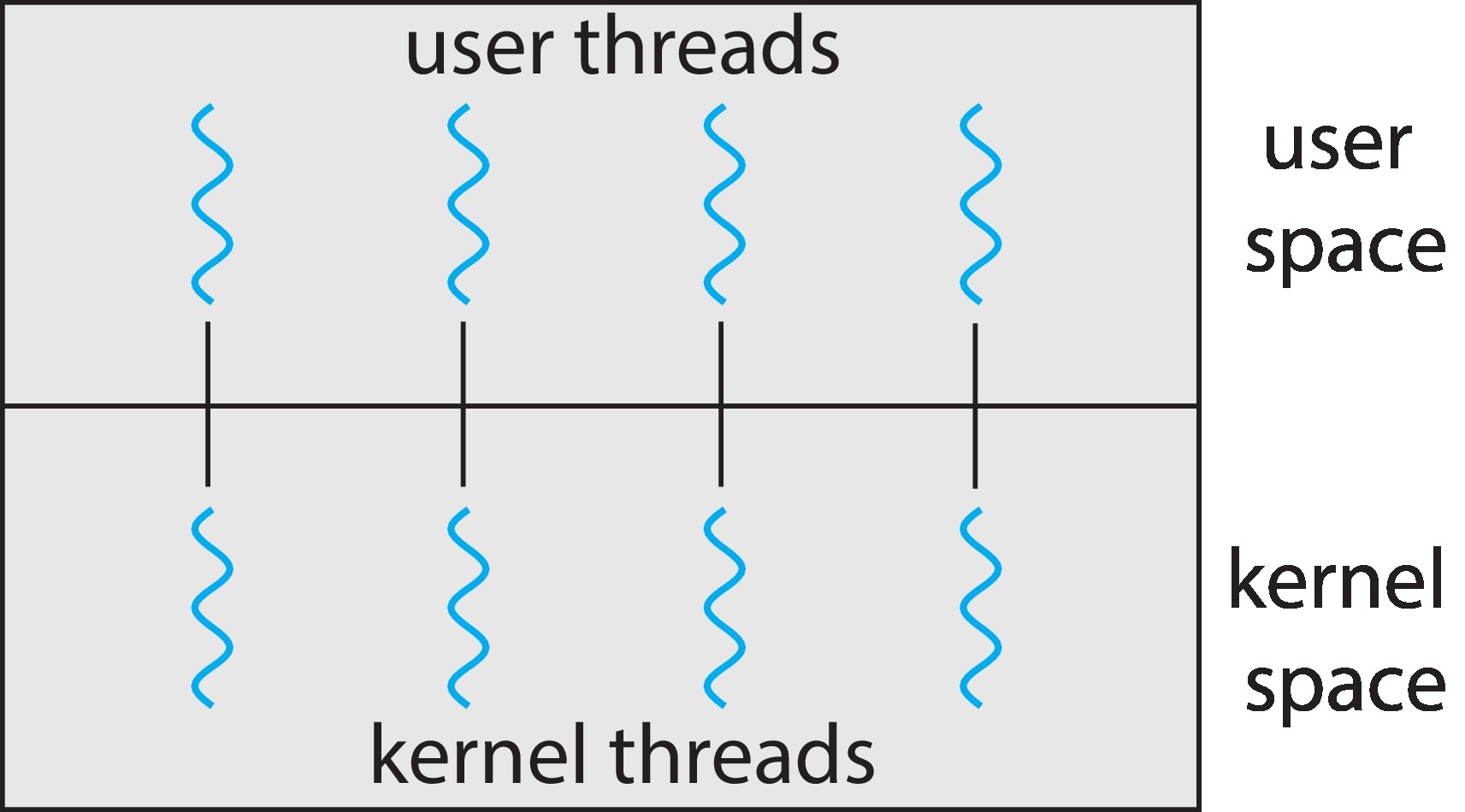
Figure 4.8: One-to-one model
4.3.2 One-to-One Model
In the one-to-one model, the number of user-level
threads is equal to the number of
kernel-level threads. Each user-level thread has exactly one supporting
kernel-level thread. Each of the kernel-level threads supports exactly one
user-level thread.
If we use the one-to-one model, we cure problems of the
many-to-one model.
Now, if one user-level thread blocks, the others don't have to block.
Also user-level threads can operate in parallel
on a multiprocessor.
However,
because each kernel-level thread supports only one user-level
thread, we
lose the advantage of quick context switches between user-level threads.
Also each time we create a new user-level thread, we need to create
a new kernel-level thread to support it, so we tend to use up more
time creating threads.
There is less flexibility to schedule the user-level threads. The
kernel decides when to run the supporting kernel-threads.
This model may lead to excessive numbers of kernel-level threads,
which could adversely affect performance.
Despite the disadvantages listed above, many operating systems use the
one-to-one model. It's relatively easy to implement, and the
disadvantages are viewed as acceptable because many systems
have a large number of processing cores that will support large
numbers of kernel-level threads.
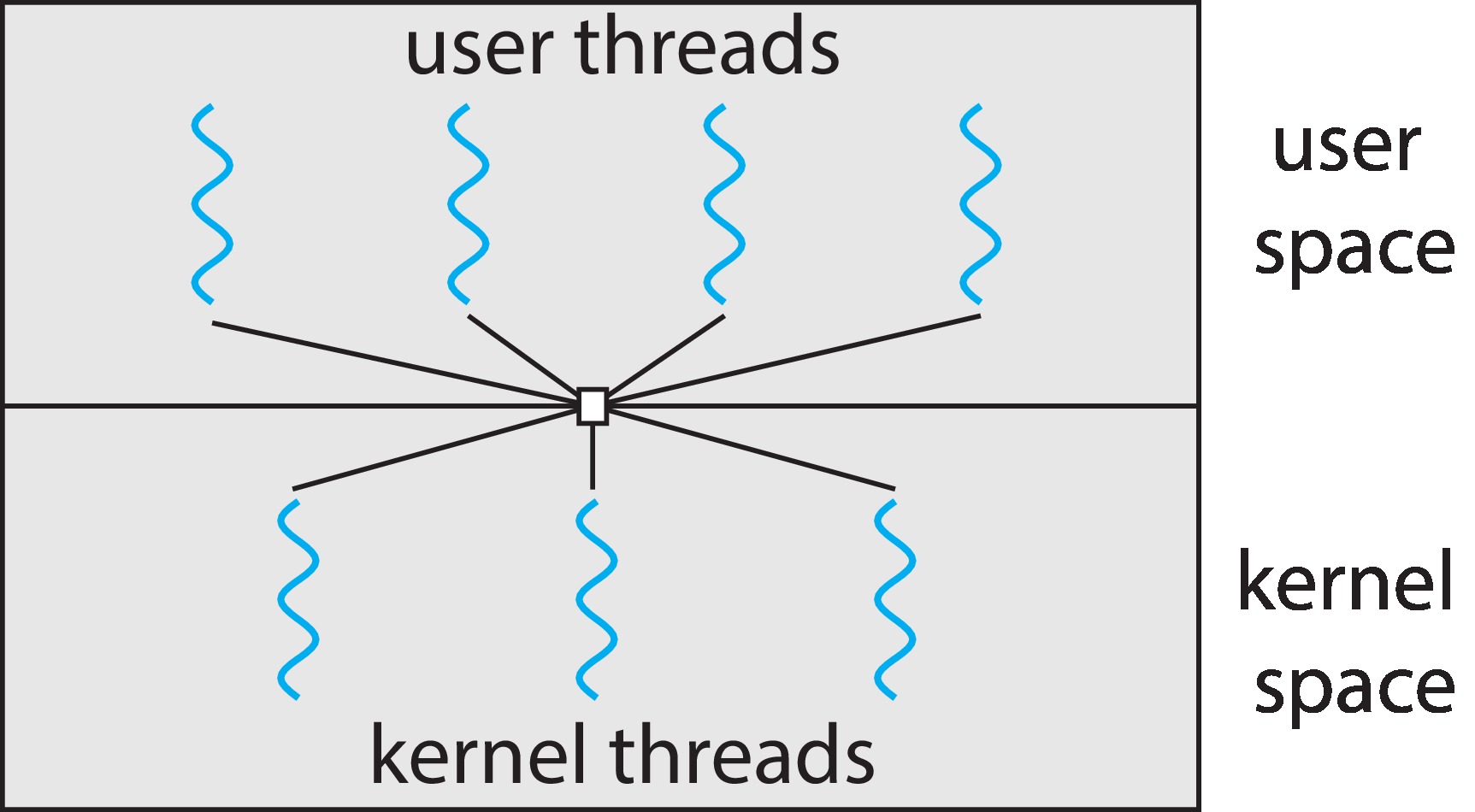
Figure 4.9: Many-to-many model
4.3.3 Many-to-Many Model
In the many-to-many model, a set of user-level threads
is supported by
a smaller or equal number of kernel-level threads. A user-level
thread is not necessarily bound to any particular kernel-level
thread. The thread library can re-assign it. For example if
a kernel-level thread X has to block, some of the user-level threads
that X was supporting can migrate for support to different kernel-level
threads.
The many-to-many model can be seen as a good compromise
between the many-to-one and one-to-one models. The many-to-many
model allows the creation of a large
multiplicity of user-level threads that may switch context
with great rapidity. The application can have greater control
over the scheduling of the user-level threads.
Much of the
advantage of the one-to-one model remains: parallelism and
independent blocking.
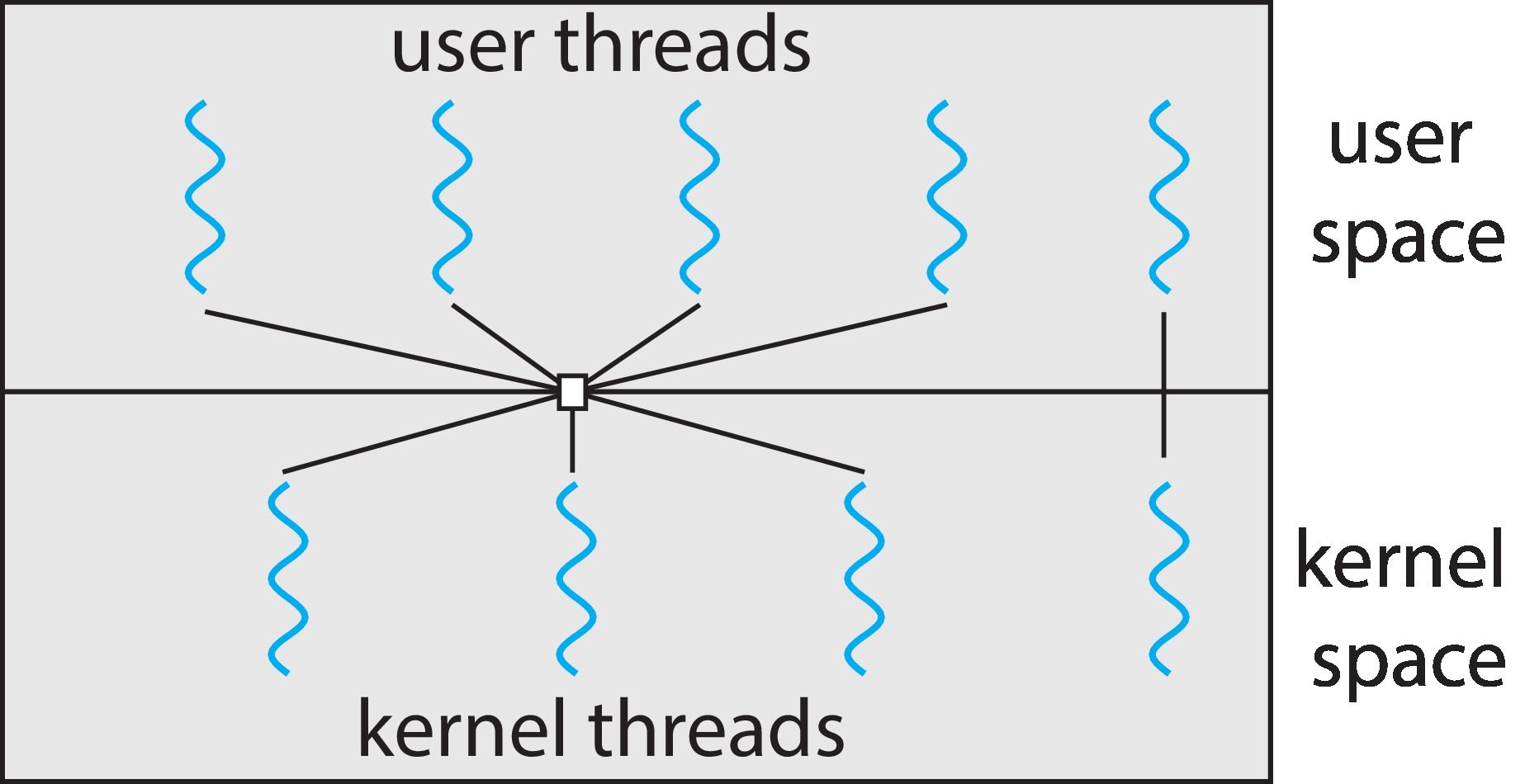
Figure 4.10: Two-level model
The two-level model is a variation on the many-to-many model,
in which a user-level thread may be bound to a kernel-level thread.
It is difficult to implement the many-to-many model, which is
one of the reasons that more operating systems do not support it.
4.4 Thread Libraries
Posix thread (pthread) implementations vary from system to system -
could be user-level or kernel-level.
Windows threads are kernel-level
The Java thread API is typically implemented using a native thread
package on the host system (e.g. Pthreads or Windows).
In asynchronous threading, the parent creates
one or more child threads and then executes concurrently with them.
In synchronous threading, the parent creates one or more
child threads and waits for all the child threads to exit
before resuming execution.
Section 4.4 contains three examples in which a parent thread
creates a child thread to execute a function. The parent
blocks until the child has exited, and then the parent
resumes execution.
4.4.1 Pthreads
If a variable is declared in a program, and it's outside
of any function, then it is automatically in memory
shared by all threads of a process. So that makes it
very easy to set up an area of shared memory.
&tid is the address of a variable to store the
id number of the thread.
&attr is the address of a data structure containing
attributes for the new thread to have.
fname is the name of the function where the
new thread will begin execution.
paramPtr is a pointer to the parameter that will
be passed to fname when the new thread
executes fname.
Figure 4.11: Multithreaded C program using the Pthreads API
4.4.2 Windows Threads
As with POSIX, in the Windows API,
if a variable is declared in a program, and it's outside
of any function, then it is automatically in memory
shared by all threads of a process. So that makes it
very easy to set up an area of shared memory.
The basic idea of implicit threading is
automation.
Developers and programmers identify tasks that can run in parallel,
and compilers and run-time libraries, or other software,
create and manage threads to perform those tasks.
4.5.1 Thread Pools
The main thread of a busy Internet server does not have time to
'personally' perform the service for each client,
because it needs to return immediately to the job of accepting
the incoming request from the next
client.
One way to deal with that problem is for the main thread
to spawn a child, a service thread, for each client.
The service thread then handles the
client request and terminates.
However it can take excessive time for the creation and termination
of the service threads, and if too many client requests come in too
fast, there may be too many service threads taxing system resources.
The idea of a thread pool is for the server to create a fixed number
of service threads at the time of process start up, and to allow them
to 'stay alive' as long as the server operates. The service threads
that don't have anything to do are kept suspended. When a client
needs service, and if a service thread is available,
the main thread assigns one to the client. Otherwise the main
thread puts the client in a queue where it waits for a service
thread to become available.
When a service thread finishes with a client, it does not terminate.
It just 'goes back to the pool' and waits to be assigned to another
client.
Generally it takes
less time for a server process to use an existing
thread to service a request than to create a brand
new service thread. Also,
no matter how much the server is flooded with client requests, the
number of service threads never exceeds the fixed
size of the pool.
One opportunity to exploit the idea of implicit threading is to program
the "thread pool architecture" to monitor the frequency of client
requests and
dynamically adjust the size of the thread pool to match demand.
4.5.1.1 Java Thread Pools
4.5.2 Fork Join
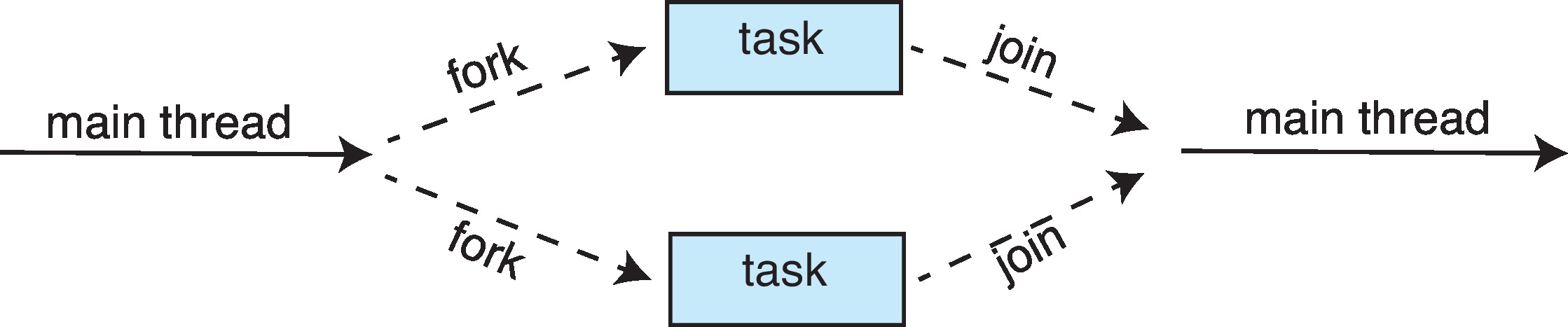
If programmers leave notations in the programs designating work
that can be performed in parallel, then implicit threading library
code can create (fork) child threads to do the work, and arrange
for the children to return results to the parent (join the parent)
when they terminate.
Figure 4.16: Fork-join parallelism
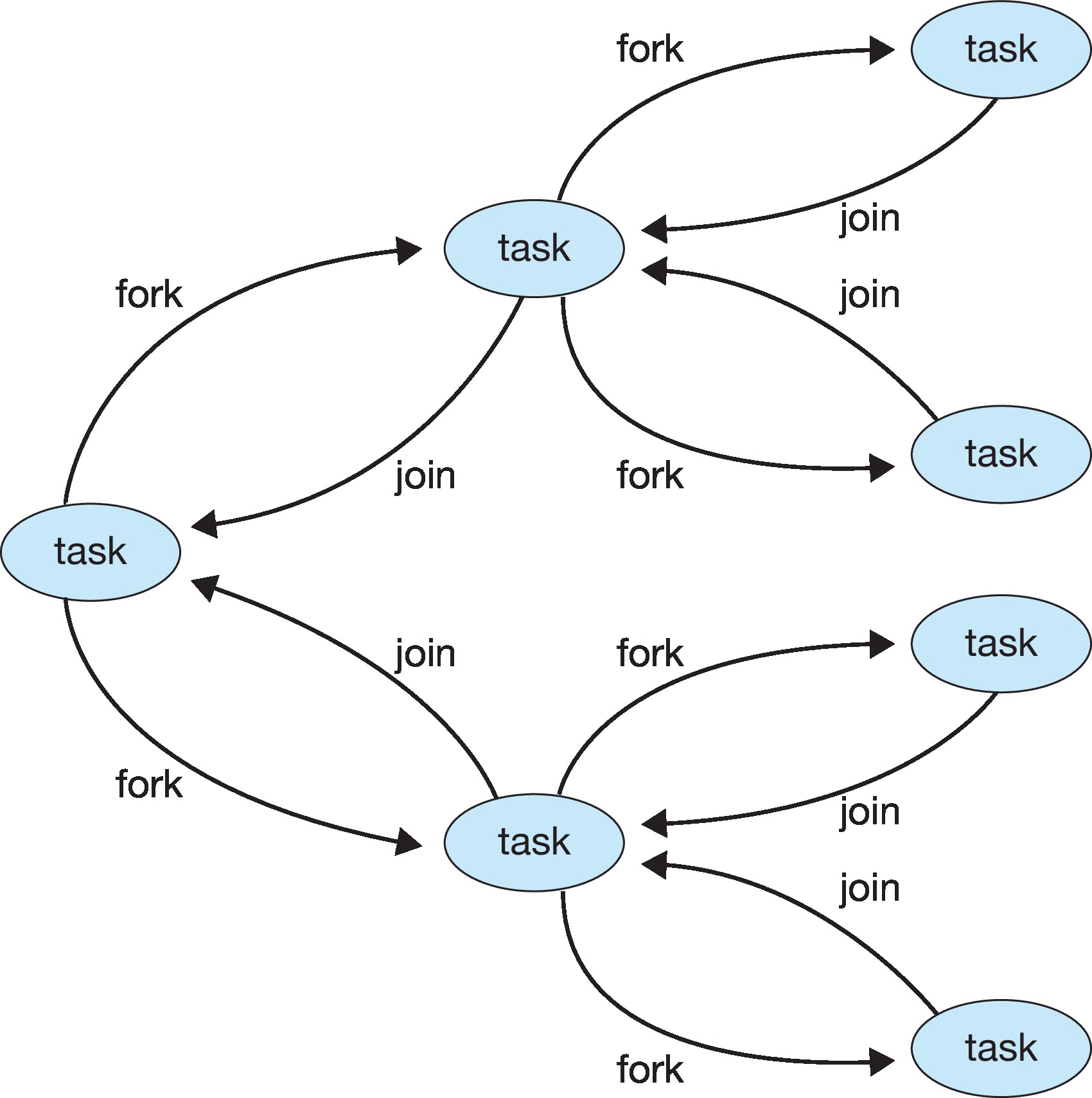
4.5.2.1 Fork Join in Java A version of Java
has a fork-join library that spawns threads to perform recursive
calls in algorithms like Mergesort.
Figure 4.17: Fork-join in Java
4.5.3 OpenMP (compiler add-on and API
for C, C++, and FORTRAN)
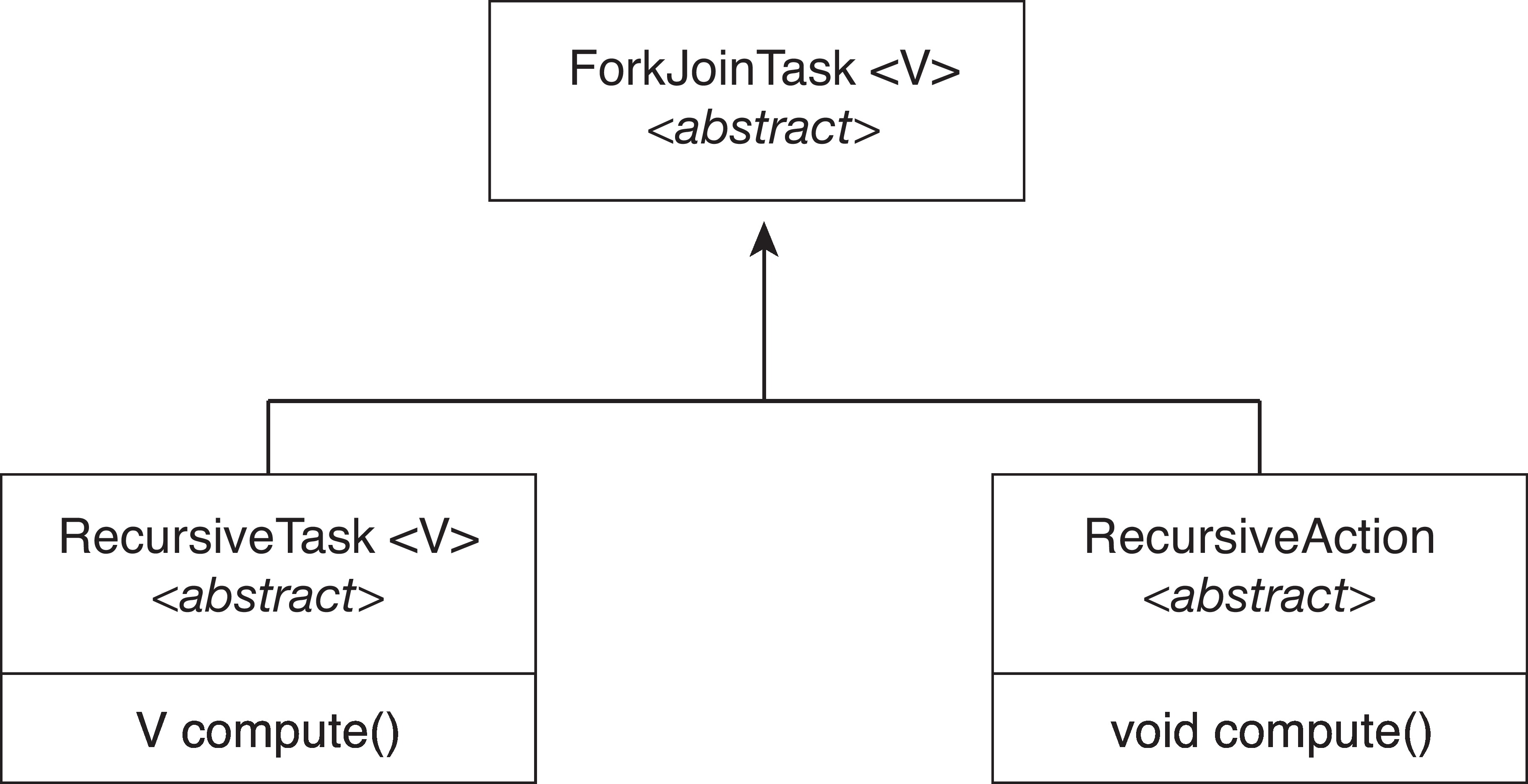
Figure 4.19: UML Class diagram for Java's fork-join
A programmer can insert labels in the code that
identify certain sections that should be executed by parallel
threads. The compiler responds to the labels by generating code
that creates threads that execute those sections of code
in parallel.
4.5.4 Grand Central Dispatch is comprised
of extensions to C, an API, and a run-time library.
Like OpenMP, it provides parallel processing,
although details of the implementation differ.
4.5.5 Intel Thread Building Blocks is another
approach to implicit threading that relies on templates for
parallel structures and task scheduling, rather than special
compilers or language features.
4.6 Threading Issues This section summarizes "issues"
that have to be resolved by people who implement operating systems
that support multi-threading.
4.6.1 The fork() and exec() System Calls
When an application is multi-threaded,
should the fork()
system call duplicate all threads, or just the calling thread?
Some API's provide both options.
Implementations of exec() typically replaces the entire process
of the calling thread, including all threads in that process.
Therefore, if the child created by a
fork() is going to call exec() immediately, there's no point
in having the fork() duplicate all the threads in the process.
4.6.2 Signal Handling
Signals are a simple form of interprocess communication in some
operating systems, primarily versions of unix. Signals were designed
to behave something like interrupts, but they are not
interrupts.
The OS delivers and handles signals.
Delivering signals and
handling (responding to) signals are routine
tasks the OS performs as opportunities arise. Sometimes delivery
of a signal to a process (or thread) is required as part of the
OS performance of interrupt service, or a system call.
The OS delivers signals to a process (thread) by setting a
bit in a context variable of the process (thread). Just
before scheduling a process (thread) to execute, the OS checks
to see if any signals have been delivered to the process (thread)
that have not been handled yet. If so, the OS will cause the
signal to be handled properly. Sometimes it does this by
executing code in kernel mode, and sometimes it handles a
signal by jumping into the user process at the start address
of a special handler routine the process has for responding
to the signal.
The exact appropriate way of handling a signal depends on the
nature of the signal.
Multithreading complicates the problem of implementing signal
delivery.
Should a signal be delivered to all the threads in a
process or just some? There are many different kinds
of signals, and the answer to that question differs, depending on
the nature of the signal.
Often the handler for a signal should run only once. A signal sent
to a process may be delivered only to the first thread that is not
blocking it.
The OS may provide a function to send a signal to one particular
thread.
4.6.3 Thread Cancellation
Sometimes a thread starts work but it should be cancelled
before it finishes - for example if two threads are searching
a database for a record and one of them finds it, the other
thread should be cancelled.
Thread cancellation can be implemented in a manner similar to how
signals work. In fact it may be implemented using signals.
Since
problems could be caused by instantly
cancelling a thread in a task that is in the midst of doing some
work, the implementation of cancellation typically includes ways
for threads to defer their cancellation so that they have time
to 'clean up' first - for example to deallocate resources they
are holding, or to finish updating shared data.
4.6.4 Thread Local Storage
Typically threads have some need for thread-specific data
(thread local storage). This is
data not shared with other threads. In Pthreads processing,
local variables can play this role, but
local variables exist
only within one function, so provision for thread local storage
that is 'more global' may be needed. Most thread APIs provide
support for such thread local storage.
4.6.5 Scheduler Activations
This section describes some rather arcane details of how
the relationship between user-level threads and kernel-level
threads may be implemented.
The "Scheduler Activation" scheme for simulating threads at the
user level relies to a great extent on the kernel communicating
about certain events to the application that is executing
the user-level threads. These communications come from the
kernel and go "up" to the application, and they are named
upcalls. Read the information, but I won't ask you for
any details.
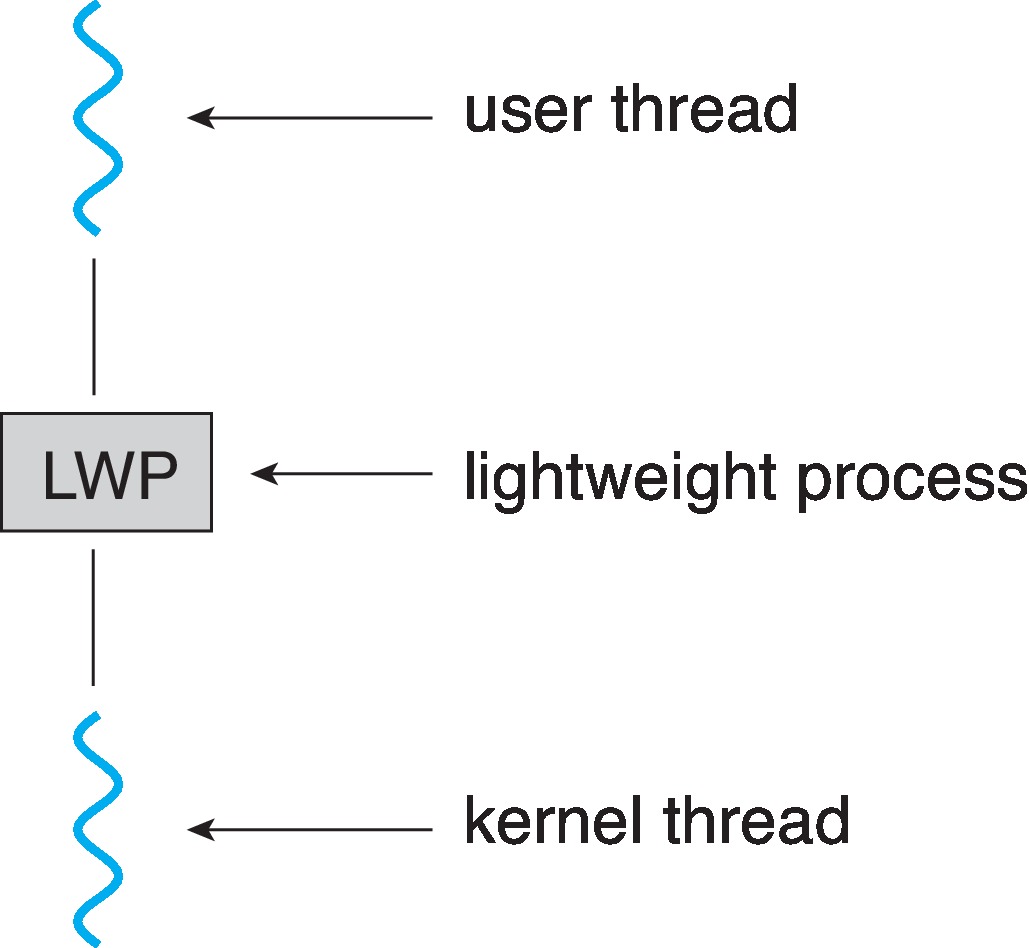
Figure 4.20: Lightweight process (LWP)
4.7 Operating-System Examples
4.7.1 Windows Threads
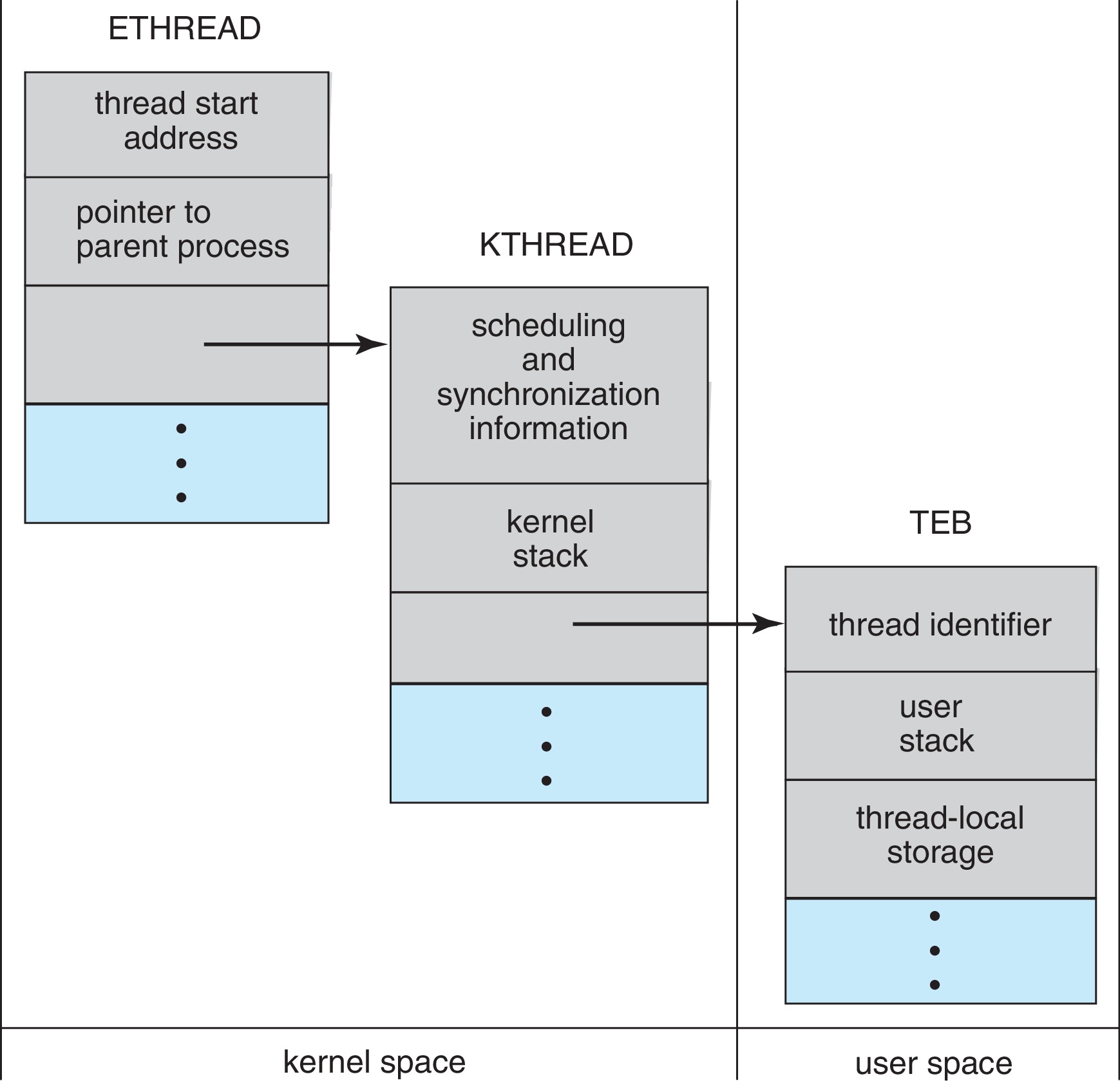
Figure 4.21: Data structures of a Windows thread
In Windows, applications run as separate processes, which may have multiple
threads. Per-thread resources include, ID number, register set,
user stack and kernel stack (for the use of the OS when executing
in behalf of the process, for example when executing a system
call for the process), and private storage used by library code.
There are three primary data structures for holding the context
of threads: ETHREAD (executive thread block), KTHREAD
(kernel thread block), and TEB (thread environment block). The first
two reside in kernel memory, and the TEB is in user-space.
4.7.2 Linux Threads
Linux has a traditional fork() system call that creates an
exact duplicate of the parent.
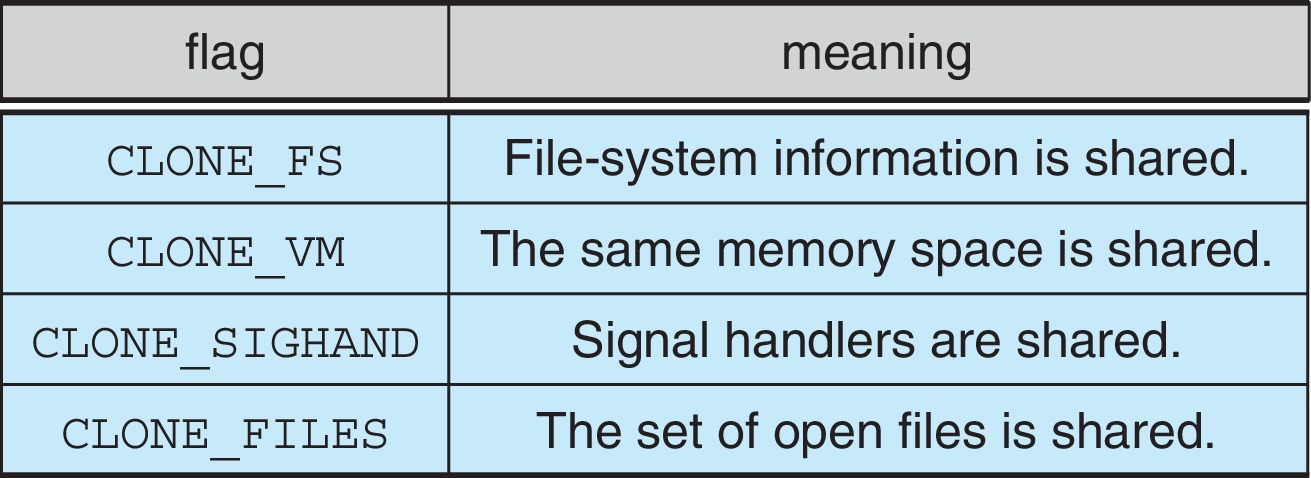
Linux also has a clone()
system call with flag parameters that determine what
resources will be shared between parent and child (clone). If a large
amount of context is shared between parent and clone, then the
clone is about the same thing as what we have before called
a new thread inside the parent process.
On the other hand, if nothing is shared, then the clone is
about the same as the child of a traditional fork() operation.