(Latest Revision:
Oct 30, 2008
)
Chapter Seven -- Deadlocks -- Lecture Notes
- 7.0 Objectives
- Description of Deadlock
- Present Methods for Preventing or Avoiding Deadlock
- Present Methods for Detecting and Recovering from Deadlock
- 7.1 System Model
- Our model system contains processes and resources.
- The set of all resources is partitioned into equivalence classes
called resource types.
- Examples of resources: CPU cycles, printers, drives, memory, files,
semaphores.
- A running process may request resources at any time.
- A process uses resources according to this pattern:
request-use-release.
- A process may request multiple resources at the same time. However
the request may not exceed the number existing in the system. For
example if there are two tape drives and four DVD's in the system,
the process may request up to (but no more than) two tape drives and
four DVD's with one request.
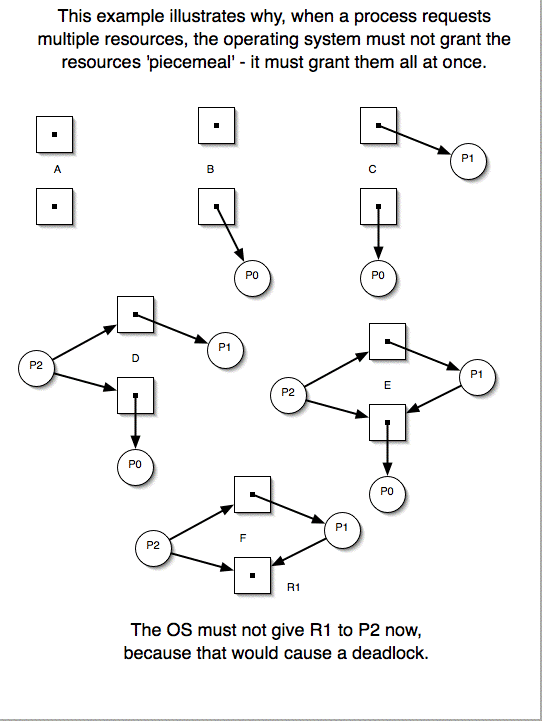
- A process must wait until everything it has requested can be granted
- all at once. (Why is this
necesary?)
- The request and release operations may be implemented as system
calls or through the use of synchronizations tools such as
semaphores.
- Deadlock occurs in a group of processes when each
process is waiting for a resource that can only be acquired when one
of the other processes in the group releases it.
- A deadlock is stable. None of the processes involved can acquire
all the resources for which it is waiting.
- 7.2 Deadlock Characterization
- Section 7.2.1 -- Necessary Conditions
- Mutual Exclusion -- If multiple processes are
permitted to access all resources concurrently then deadlock
can't happen.
- Hold and Wait -- If processes never hold a resource
while waiting for a resource then deadlock can't happen.
- No preemption -- If "enough" preemption of resources
occurs, then deadlock can't happen. (In the extreme,
suppose that whenever a process waits for a resource the
system takes away all the resources it currently holds.
Deadlock would be impossible. )
- Circular Wait -- If cycles in the resource
allocation graph cannot occur then there cannot be any
deadlock.
- Section 7.2.2 -- Resource-Allocation Graph (RAG)
- Processes are Nodes -- Circles
- Resource Types are Nodes -- Squares
- Each instance of the resource type is represented by a
dot in the square
- A solid request-edge points from a process to a resource
type
- When a request is granted the request edge is instantaneously
transformed into an assignment edge extending from one of the
instances inside the resource to the process.
- If there are no cycles in the RAG then there is no
deadlock in the system.
- If there is only one instance of every resource type, and if
there is a cycle in the RAG then the processes on the cycle are
deadlocked.
- If some of the resource types have more than one instance
then it is possible for a cycle to exist in the RAG when
there is no deadlock.
- 7.3 Methods for Handling Deadlock
- Deadlock Prevention: Make rules about how requests and
assignments are done so that one or more of the necessary conditions
for deadlock are missing.
- Deadlock Avoidance: Place restrictions on assignments only
when the system is about to enter an "unsafe state" - from which it
could immediately "go out of control" and become deadlocked. (The
avoidance algorithms we study require extra, advance information
concerning the types and numbers of resources each process could
request during its lifetime.)
- Deadlock Detection and Correction: Place no restrictions on
the system but notice when deadlock has occurred and recover.
- Ignore the problem: Maybe deadlocks are rare and we can deal
with the problem just by rebooting when we notice that some
processes appear "frozen." This will not always be adequate -
imagine that the computer is flying a plane.
- 7.4 Deadlock Prevention (ways of preventing cycles from forming)
- Mutual Exclusion: If X is a resource and the OS immediately
grants every request for access to X, then X can never be part of a
circular wait - it can never be 'involved' in a deadlock. For
example, it is OK for any number of processes to share a read-only
file. Obviously sometimes exclusive access to resources is required.
So we can't prevent deadlock simply by deciding to make all
resources sharable all the time.
- Hold and Wait:
- Method: Require each process to request and be allocated all its
resources before it begins execution, or
- Method: allow a process to request resources only when it has
none.
- Disadvantage of these methods: resources may be allocated
but unused for long periods of time.
- Disadvantage of these methods: If a process waits for more than
one resource, there is no guarantee they will all become
available at the same time.
- No Preemption:
- Method: If a process P requests a resource that is not
immediately available, P immediately loses all resources it
holds and is required to wait for the new resource, plus all
its 'old' resources.
- Method: Suppose a process P requests some resources that are
held by a process Q. If Q is waiting for a resource
then P takes what it wants from Q and this is added to the
request for which Q is waiting. (If no process waits on a
waiting process then there are no cycles.) If Q is not
waiting then P waits. (The OS can preempt stateless things like
registers and memory without harming Q. However if it takes
away something like a printer, it may as well terminate Q.)
- Disadvantage of these methods: More time lost waiting for
resources, including the possibility of indefinite postponement
when waiting for multiple resources.
- Circular Wait:
- Method: Impose a total ordering on resource types and forbid
requests that go against the order. (Also a process may not
make consecutive requests for instances of the same resource
type.) These rules assure that, in chains of waiting
processes, the resource numbers are strictly increasing, and so
there cannot be any cycles.
- Disadvantage of this method: It may lead to longer periods of
holding some resources, and thus to decreased availability of
resources.
- 7.5 Deadlock Avoidance
- The idea of deadlock avoidance is for the OS to recognize unsafe
states - states from which the system could slip, out of
control, into deadlock. To recognize unsafe states, the OS needs to
have information about the possible resource needs of each
process.
- Section 7.5.1 -- Safe State
- Basically an unsafe state is one which will turn in to a
deadlock if all processes immediately request their remaining
possible needs.
- The state is safe if it is not unsafe. If the system state is
safe then even if all processes max out their requests, they
are able to finish executing in some order P0,
P1, P2, ... , Pn. When each
process exits, it gives up its resources. Freed resources
become available to the next process in the sequence.
- When a system practices deadlock avoidance it uses the
following criteria to decide whether to grant resources to a
requesting process P. The request is granted if:
- P is not asking to exceed its declared maximum possible
needs,
- the resources are currently available (free), and
- granting the request will leave the system in a safe
state.
Typically if P tries to exceed its max, the OS will terminate
P. If condition #1 is true but #2 or #3 fails, the system
makes P wait for the resources. (They will be granted later -
when available and 'safe.')
- PROBLEMS WITH THAT: The system is burdened with doing a safety
check each time there is a resource request. Processes
sometimes have to wait for resources that are available.
Resource utilization and throughput can be reduced. There is
also the possibility of
starvation.
- Section 7.5.2 -- Resource-Allocation Graph
- We can create an augmented resource allocation graph (AUGRAG)
by adding (dotted) claim edges from processes to resources,
representing each request that each process might make.
- If there is just one instance of each resource type, then
"unsafe" is equivalent to "cycle in the AUGRAG." This is a
conceptually simple way to characterize safety. Cycle
detection algorithms typically require O(N2) work,
where N is the number of processes in the system. This method
does not work when there are multiple instances of some
resource types, because in that case there can be a cycle in
the AUGRAG of a safe system.
- Section 7.5.3 -- Banker's Algorithm
- The Banker's Algorithm is a deadlock avoidance scheme that
works when there are multiple instances of resource types. It
is generally less efficient than the cycle-detection scheme.
- Before it does anything else a new process must declare the
maximum number of instances of each resource type that it may
need.
- Various data structures are required. See the GLOSSARY
here.
- Section 7.5.3.1 -- Safety Algorithm
- Read the algorithm to check for safety
here.
- Section 7.5.3.2 -- Resource Request Algorithm
- Read the banker's resource-request algorithm
here.
- Section 7.5.3.3 -- An Illustrative Example
- 7.6 Deadlock Detection
- Another alternative: Have the system run a deadlock detection
algorithm and have the system run a recovery algorithm after it
detects a deadlock.
- Section 7.6.1 -- Single Instance of Each Resource Type
- In this case there is a deadlock if and only if there is a
cycle in the resource allocation graph. Therefore the OS can
detect deadlock by maintaining a RAG that represents the system
and doing cycle checks from time to time. There is a more
compact graphical representation called a wait-for graph
that can be used instead. The algorithm will tend to be more
efficient if run on this graph.
- Section 7.6.2 -- Several Instances of a Resource Type
- If there are multiple instances of some resource types then one
can detect deadlock with an algorithm similar to the safety
algorithm. (We can view the safety algorithm as checking to
see if there would be a deadlock if all the processes were to
max out their requests.)
- See
the deadlock detection algorithm.
- Section 7.6.3 -- Detection-Algorithm Usage
- In the system model we use, the addition of a request edge to a
RAG is always the last step in the creation of a deadlock. If
we check for deadlock every time a process blocks requesting a
resource, then we will detect each deadlock as soon as it
happens. Using our textbook's deadlock detection algorithm, this
would require a lot of processing - a lot of overhead.
- Since deadlocks are usually quite rare, it may suffice to check
for deadlock only about as often as deadlock occurs. We also
might make use of heuristics, such as low CPU utilization or the
presence of processes in the system that have been waiting for
resources for an unusually long time.
- 7.7 Recovery from Deadlock
- Section 7.7.1 -- Process Termination
- To break a deadlock we can just abort all the deadlocked
processes. However, much of their unfinished work will go to
waste.
- Instead we can select and abort victim processes one at
a time, stopping when the deadlock is broken. This brings up
the question of what criteria to use to select victims:
- Kill the lowest priority process?
- Kill the youngest process?
- Kill the process that has most "life" ahead of it?
- Kill the process with the fewest stateful resources?
- Kill the process that needs the most additional
resources?
- Kill the smallest possible number of processes?
Also, there is the problem of determining when the deadlock is
broken. Will it be necessary to run an expensive deadlock
detection algorithm after each process is aborted?
- When the OS aborts a process its data and/or allotted devices
may be left in an incorrect state. Consider a process that was
in the midst of printing a file or burning a CD.
- Section 7.7.2 -- Resource Preemption
- Instead of killing deadlocked processes we can take resources
from some and give them to others until the deadlock is broken.
- We have to consider here too the bases for victim selection.
- If we don't abort a victim process we will probably need to
roll it back and restart it at a point in its execution before
it acquired the resources that have been preempted. Problem:
How?
- Starvation is a possibility when we abort or rollback processes and
restart them. There is no guarantee that they will not become
deadlocked again, and be aborted or rolled back again. We may want
to build in a mechanism to "spare" former victims.
{kind=link}