This chapter discusses file storage and access, ways to structure file use, to allocate space, recover freed space, and track locations of data. There are many different types of file systems with differing design goals and features.
- Describe the details of implementing local file systems and directory structures.
- Discuss block allocation and free-block algorithms and trade-offs.
- Explore file system efficiency and performance issues
- Look at recovery from file system failures
- Describe the WAFL file system as a concrete example
- For efficiency reasons,
I/O operations between disk and
primary memory are performed in units of blocks. A block
is N sector's worth of data, where N >= 1 is a (fixed) small
positive integer.
- Designers must decide on the logical view users will get of
a file system - what file types there will be, what their
attributes will be, what the directory structure will be,
and what means users will have for organizing files.
- Designers also must decide on the algorithms and data structures
that will be used to implement the desired logical view of the
file system.
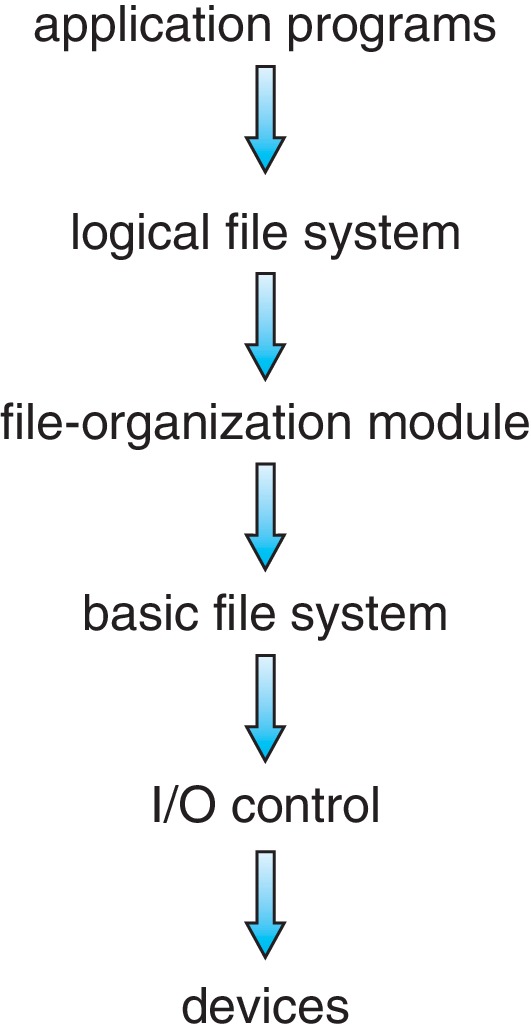
Figure 14.1: Layered file system - Often file systems have a layered design. The figure above
represents an example of a layered design.
-
At the lowest level (above the hardware) the file
system implementation consists of
the I/O control
- device drivers and interrupt handlers that implement
commands like "retrieve block 123."
- Next above the level of I/O control is
the basic file system, which issues commands
to the I/O control level to
access file blocks specified by logical block address.
The basic file system
also schedules I/O requests and manages memory buffering and
caching, of file data and metadata. Typical metadata consists
of directory information and attributes.
- The next level up is
the file-organization module,
which is
concerned with keeping track of the logical blocks of files, as well as
free-space management.
- Next up comes
the logical file system
which
manages the metadata,
like directories, and per-file file control block structures
that contain file attributes. This layer is also responsible
for protection.
- An operating system can support many different file systems, and typically multiple file systems can utilize the same I/O control module. Perhaps multiple file systems can also have large portions of their basic file system modules in common Such sharing and avoidance of duplication of code is an advantage of a layered design. However overhead introduced at each layer can affect file system efficiency negatively, which is a major concern because of the fact that delays caused by access to secondary storage are often a major bottleneck in a computing system.
-
14.2.1 Overview
- Various
metadata structures on secondary memory
are utilized to implement file systems. Here are
examples:
- per volume boot control block - typically the first block on the volume. On a bootable volume it has info the computer uses to boot the OS from the volume. (examples: UFS boot block and NTFS partition boot sector)
- volume control block - info like the number of blocks on the volume, the block size, the free-block count, pointer(s) to free blocks, free-FCB count, and pointer(s) to free FCBs (examples: UFS superblock and NTFS master file table)
- directory structure
- per-file file control block (FCB)
-
Other metadata structures are utilized
in primary memory, for aspects of file system
management, and to facilitate file access
and enhance efficiency. Examples include:
- mount table - info about each mounted volume
- directory-structure cache - info on recently-accessed directories
- system-wide open-file table - copies of the FCBs of open files, and other info
- per-process open-file table - contains some per-process info and a pointer to an entry in the system-wide open-file table
- buffers to hold file blocks when read from or written to secondary memory
- To create a file the OS must allocate an FCB and
add an entry to the appropriate directory. Typically the directory
entry contains the name of the file and a pointer to its FCB.

Figure 14.2: A typical file control block
- Various
metadata structures on secondary memory
are utilized to implement file systems. Here are
examples:
-
14.2.2 Usage
- When a process opens a file, the OS adds an entry
to the per-process open-file table. If no process
already has the file open, the OS also creates a
new entry in the system-wide open-file table.
There is a counter in each entry of the system-wide
open-file table to keep track of how many processes
have the file open. The system call that opens a file
returns a pointer to the appropriate entry in the
per-process open-file table. (examples: unix file
descriptor and Windows file handle)
- When a process closes a file, the OS deletes the
entry in the per-process file table and decrements
the counter in the corresponding entry in the system-wide
open-file table. If the counter goes to zero, the OS
deletes the entry in the system-wide table, after copying
any modified metadata back to disk.
- The system-wide open-file table may also be used for
managing objects with file-like interfaces, such as
devices and network connections.
- The caching of file system metadata is very important,
since it helps greatly reduce the delays caused
by file system interaction, which is a major bottleneck
in most computing systems.
- The figure below depicts some of the file system structures discussed in sections 14.2.1 and 14.2.2 above.
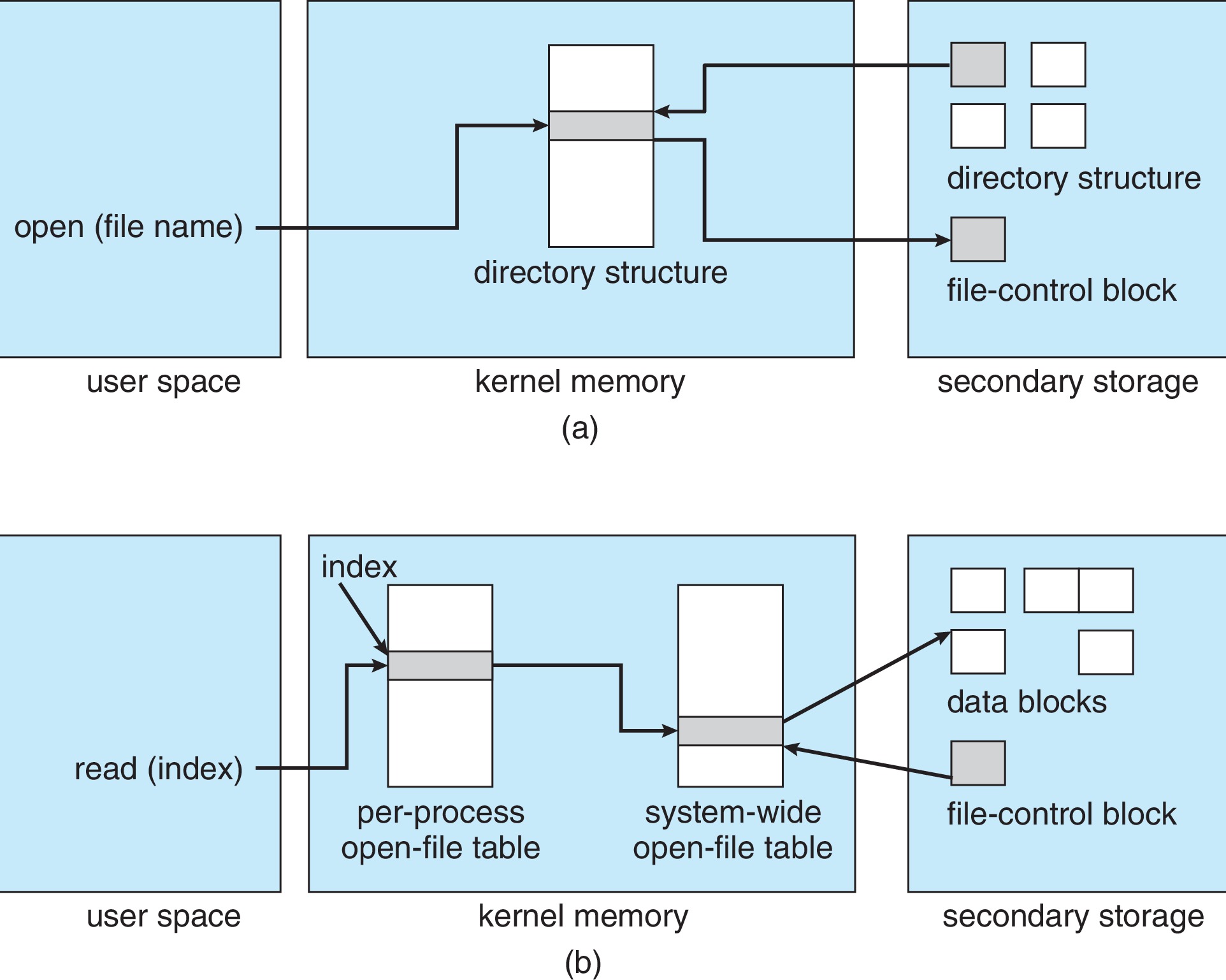
Figure 14.3: In-memory file-system structures. (a) File open. (b) File read - When a process opens a file, the OS adds an entry
to the per-process open-file table. If no process
already has the file open, the OS also creates a
new entry in the system-wide open-file table.
There is a counter in each entry of the system-wide
open-file table to keep track of how many processes
have the file open. The system call that opens a file
returns a pointer to the appropriate entry in the
per-process open-file table. (examples: unix file
descriptor and Windows file handle)
Directory-allocation and directory-management algorithms are a major design choice, affecting efficiency, performance and reliability.
-
14.3.1 Linear List
- The simplest kind of directory implementation to code would be a linear list of (file name, pointer to disk location) pairs.
- However, such a structure does not well support the complete set of symbol table operations. One is forced to settle either for sequential searching or large amounts of data movement during insertions and deletions. A balanced binary search tree with threading to support in-order and other common traversal orders would be good for larger directories, but not worth the overhead for smaller directories.
-
14.3.2 Hash Table
- One compromise is a hash table that uses chaining for collision resolution. That gives good performance for search, insertion, and deletion. The use of chaining mitigates problems stemming from the fixed size of the hash table.
- Of course, the hash table structure does not give good support for traversing the directory in filename order.
The trick to disk space allocation for file systems is to get two things at once: good storage utilization and fast file access. Contiguous, linked, and indexed allocation are the three main methods in use. There are many variations of the main methods.
-
14.4.1 Contiguous Allocation
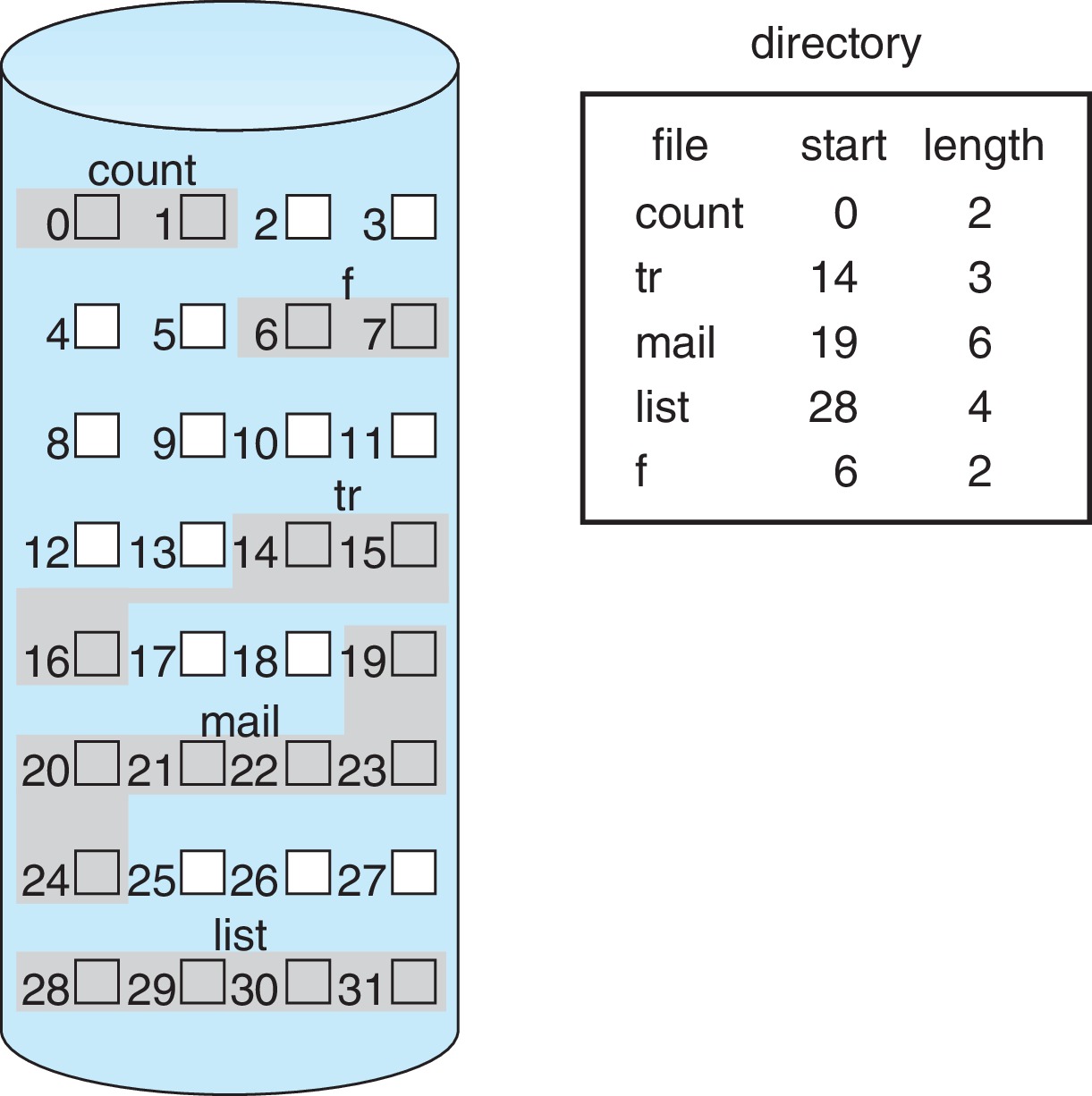
Figure 14.4: Contiguous allocation of disk space - Contiguous allocation requires that a set of contiguous
blocks on secondary memory be allocated for each file.
- A major advantage is that all blocks of the file can be
accessed with a minimal number of seeks, and with
minimal seek time.
- To keep track of which blocks are allocated to a file,
the OS only has to store two numbers in the directory
or FCB, the address B of the first block, and the number
N of blocks in the file.
- When accessing the file, it is simple to compute the physical
address of a file block from its logical address. Typically
the logical block numbers are just a range
of the form 0 .. N-1, and
the physical block number of a logical block K
is the sum B+K of the physical block number of the base block
and the logical block number.
- Because there is a quick constant-time method to calculate
the physical location corresponding to any logical block
address, contiguous allocation
easily supports both sequential
and direct file accesses.
- Unfortunately contiguous allocation has
a very serious drawback. The problem of allocating
contiguous storage on secondary memory is an instance
of the now-familiar
dynamic storage allocation problem which
means that a very significant amount of the storage
could become unusable
external fragmentation.
- Compaction of hard disks can take hours.
- It is also a problem to decide how much space should be
allocated for a file. One often does not know how large
a given file will need to grow.
Adding more contiguous
space to an existing file may seldom be possible.
There may not be any adjacent free space available.
- When users create files, they need to state how many
contiguous blocks to allocate. They may overestimate significantly
in an effort to reserve room for growth. This will likely
lead to excessive internal fragmentation.
- If we allocate the file as a linked list of contiguous extents,
this may mitigate some of the problems, but such implementations
don't support direct access well.
- The limitations of contiguous allocation motivate efforts to use forms of linked or indexed allocation.
- Contiguous allocation requires that a set of contiguous
blocks on secondary memory be allocated for each file.
-
14.4.2 Linked Allocation
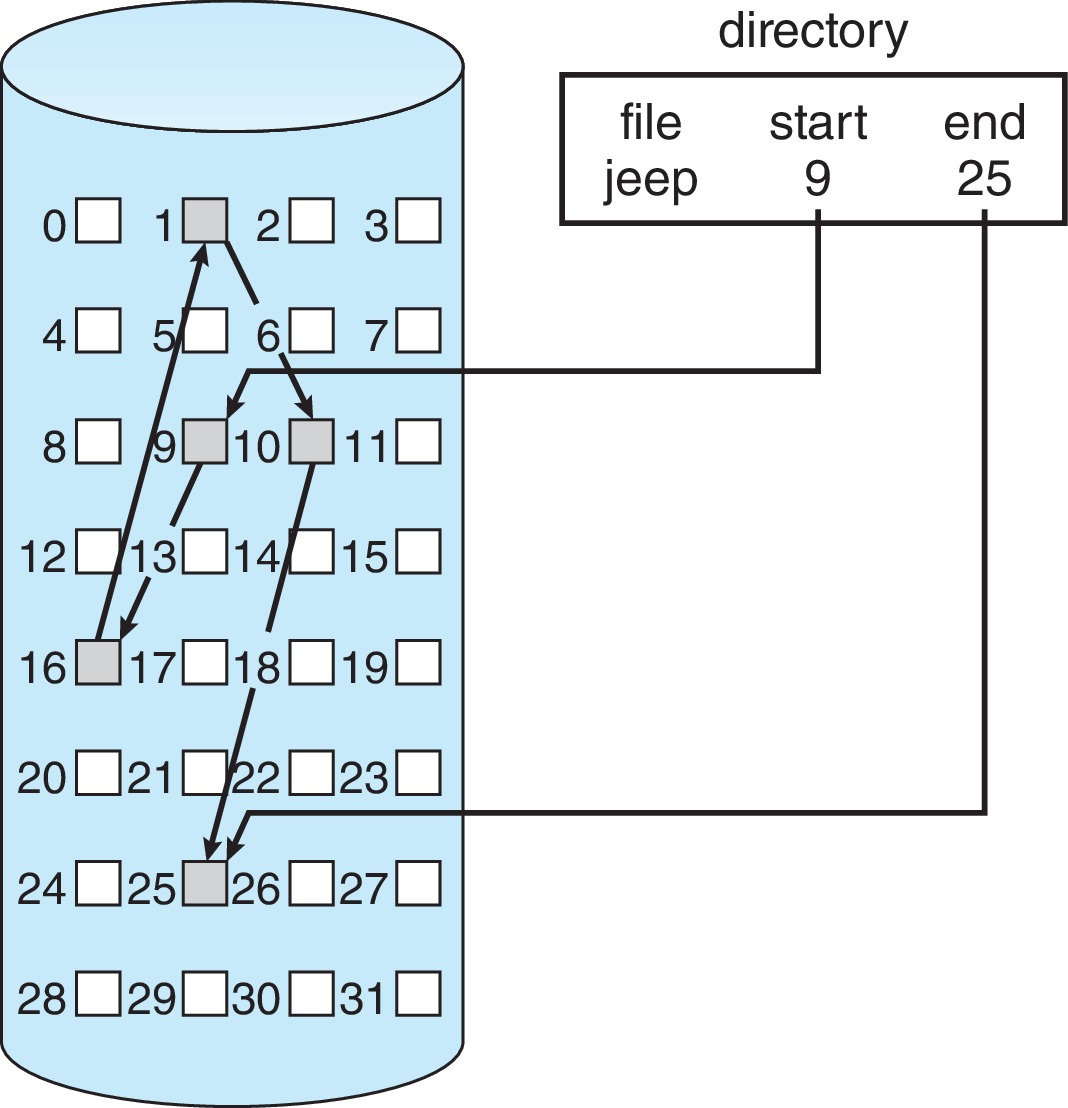
Figure 14.5: Linked allocation of disk space - With linked allocation,
each file is a linked list of file blocks.
- Linked allocation
does not suffer from external fragmentation
at all. Any block anywhere on the volume can be used in any
file any time. It is easy to add more blocks
to a file at any time. Compaction is never necessary.
- The directory or FCB contains pointers to the first and
last blocks of the file.
- One way of implementing the rest of the pointers
is to place in each data block a pointer to the
next block.
- The major problem with linked allocation is that
it supports direct access extremely poorly. Generally,
in order to get access to the Kth block of a file, it is
necessary to follow K pointers, starting with the pointer to the
first block.
- Also, since each file block can be anywhere on the volume,
the average seek time required per block access can be
much greater than is the case with contiguous allocation.
- If we link contiguous clusters of blocks instead of blocks
there will be fewer pointers to follow and the proportion
of space on disk used by pointers will be smaller. On the
other hand, the average amount of internal fragmentation
will increase.
- Reliability is a problem, since the consequences of a lost
or corrupted pointer are potentially great.
-
The concept of a file allocation
table (FAT) is a useful variation on linked
allocation. The FAT is a table stored at the beginning
of the volume, having an entry for each physical block.
It is in effect
an array, indexed by physical block number.
The pointers used to link files together are stored
in the FAT instead of in the data blocks of the file.
- As an example of how to use the FAT, suppose we want to
access logical block 2 of file X. First we consult X's
directory entry or FCB to learn the physical block number
of X's first logical block, block 0. Let's say that physical
block number is 123. We then examine the contents
of entry 123 in the FAT. Let's say 876 is stored there.
That means that 876 is the physical block number of X's
logical block 1. We then go to entry 876 of the FAT, and
find there the physical address of X's logical block 2.
Let's say that number is 546. All we have to do now is
request physical block 546.
- By putting a special sentinel value in the entries of free blocks,
the OS can implement a free-block list within the FAT.
- Using the FAT for direct access tends to require fewer seeks than with ordinary linked allocation, because all the pointers are relatively close to each other. If the FAT is small enough to keep in primary memory, then traversing the FAT would not require any seeks. (The FAT for a terabyte drive with 4KB blocks would use about a gigabyte of primary memory.) The design could enhance the reliability of the pointers by making backup copies of the FAT.
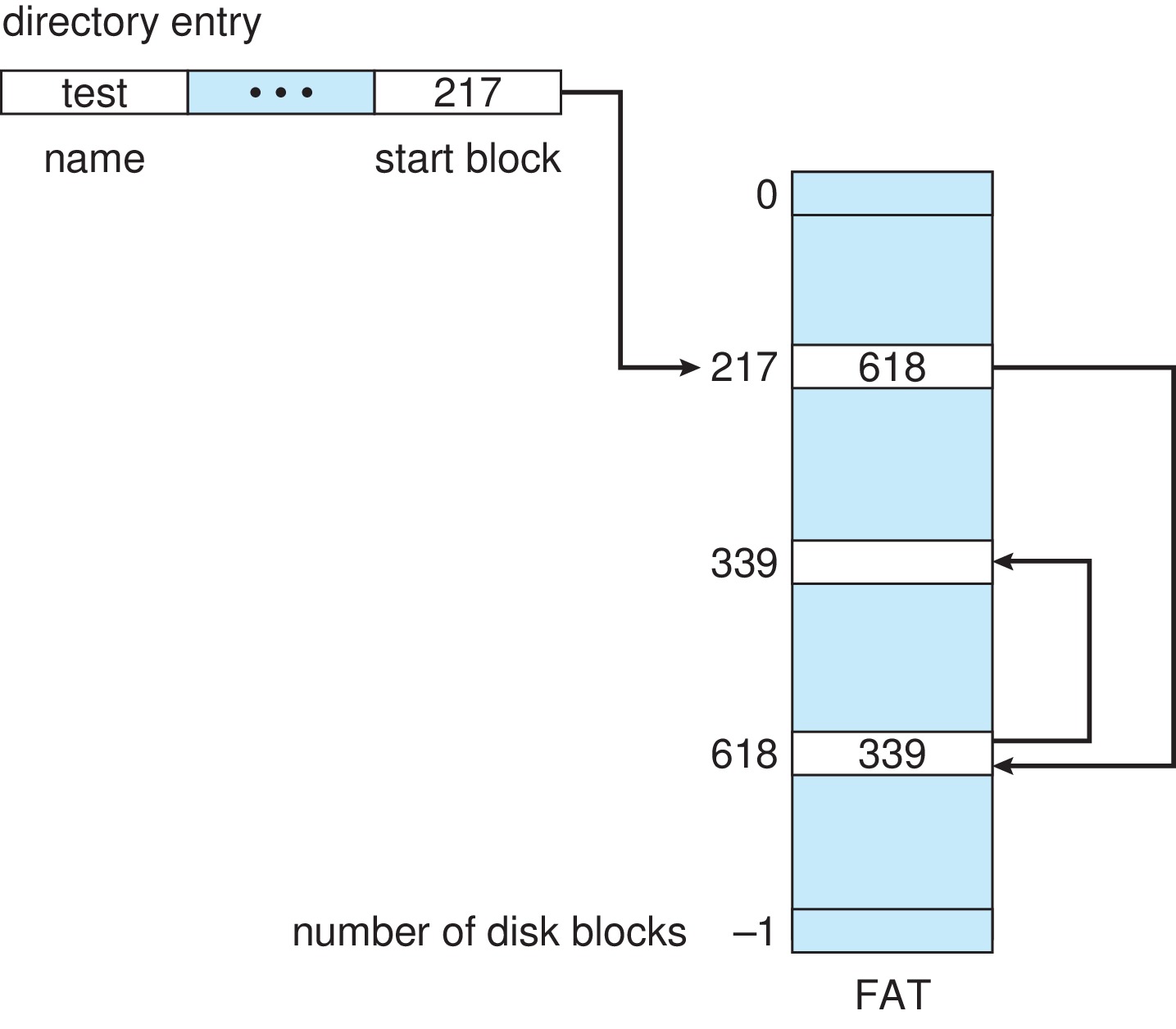
Figure 14.6: File-allocation table - With linked allocation,
each file is a linked list of file blocks.
-
14.4.3 Indexed Allocation
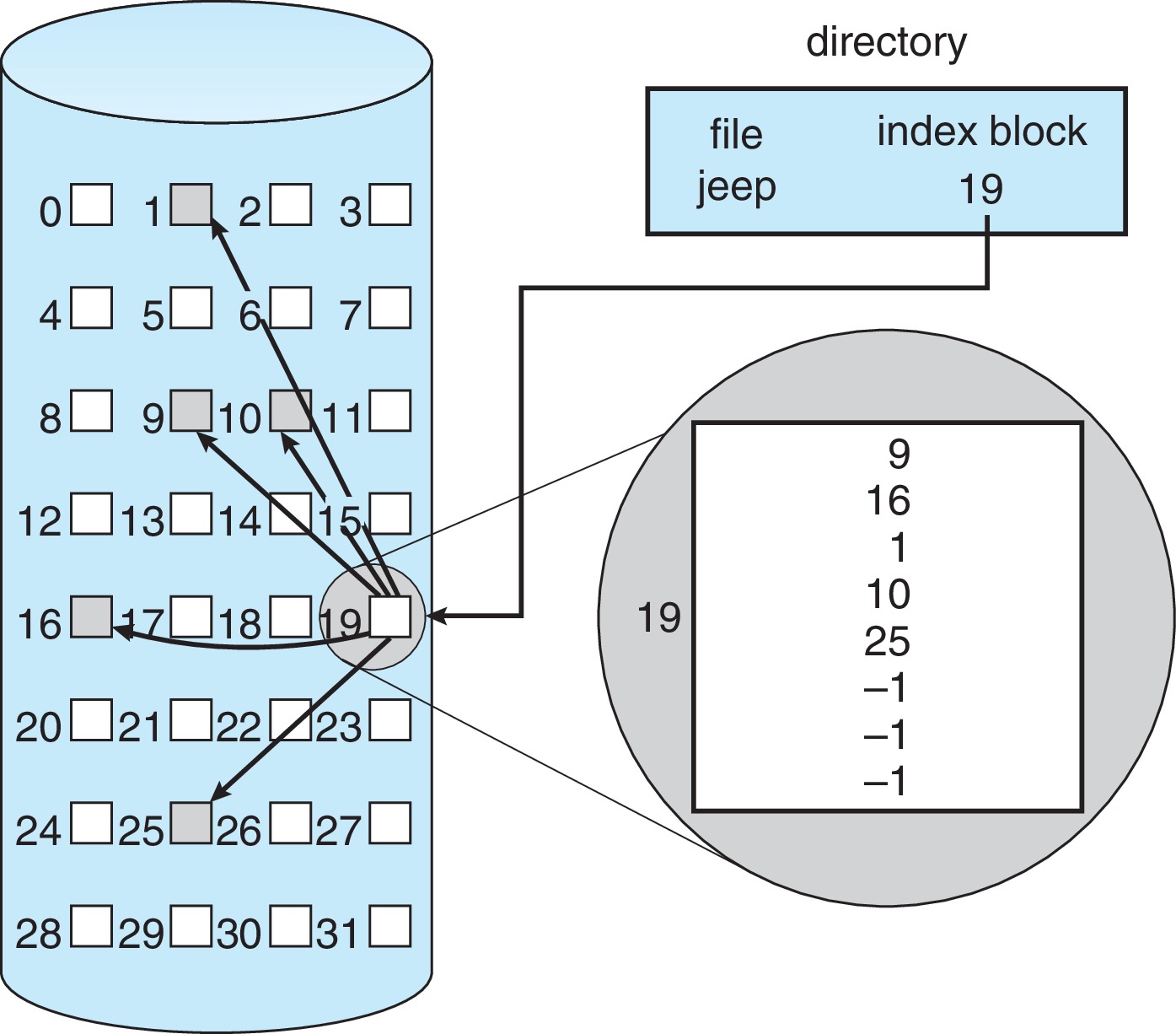
Figure 14.7: Indexed allocation of disk space - Indexed allocation
utilizes a per-file table
where all the physical addresses of the data blocks of the
file are stored.
- This table, like a FAT, is basically an array
of physical block numbers.
However, the indexes
into the array are logical block numbers.
(The indexes into a FAT are physical
block numbers.)
-
To find the kth logical block of the file, we simply
consult the kth entry in the table and read off the
physical address of the block.
- The table is usually called "the index"
- The directory or FCB would contain the address of the index.
-
The indexing scheme works pretty much the same way that
paging works in primary memory management. (The FAT
scheme is something like an inverted page table, but
that analogy is weaker.)
- With indexed allocation, there is
no external fragmentation, and the OS can support
both sequential and direct access with acceptable
efficiency.
- Internal fragmentation occurs in the last data block of files
and in the unused portions of the index blocks.
- If it is a simple one-level index, it may be possible to cache
the entire index of a file in main memory.
If so, to find the physical address of any
block in the file, it is enough just to look at a single
entry of the index. In contrast, it is likely that
there will not be enough memory to cache an entire
FAT, and on average we have to probe half the file's
FAT entries to find one of the file's data blocks.
- When using indexed allocation, each file block can be
anywhere on the volume, so
there can be a long
average seek time required for accessing
a series of blocks of the file, whether
sequentially or randomly.
With contiguous allocation, the blocks of a file are close together, so when accessing a series of blocks, the average seek time tends to be shorter than is the case with either linked allocation or indexed allocation.
- To accommodate large files, the system may resort to using
a linked list of index blocks, or a multilevel index in which
one master index points to multiple second-level index blocks
that point to file data blocks.
- The unix inode utilizes a variation on multilevel indexing. The first 12 pointers in the inode point to file data blocks. One entry of the inode points to a single indirect block, which is a block of pointers to file blocks. Another entry of the inode points to a double indirect block - a block of pointers to single indirect blocks. A third entry of an inode points to a triple indirect block, which is a block of pointers to double indirect blocks. "Under this method, the number of blocks that can be allocated to a file exceeds the amount of space addressable by the 4-byte pointers used by many operating systems" (4 GB).
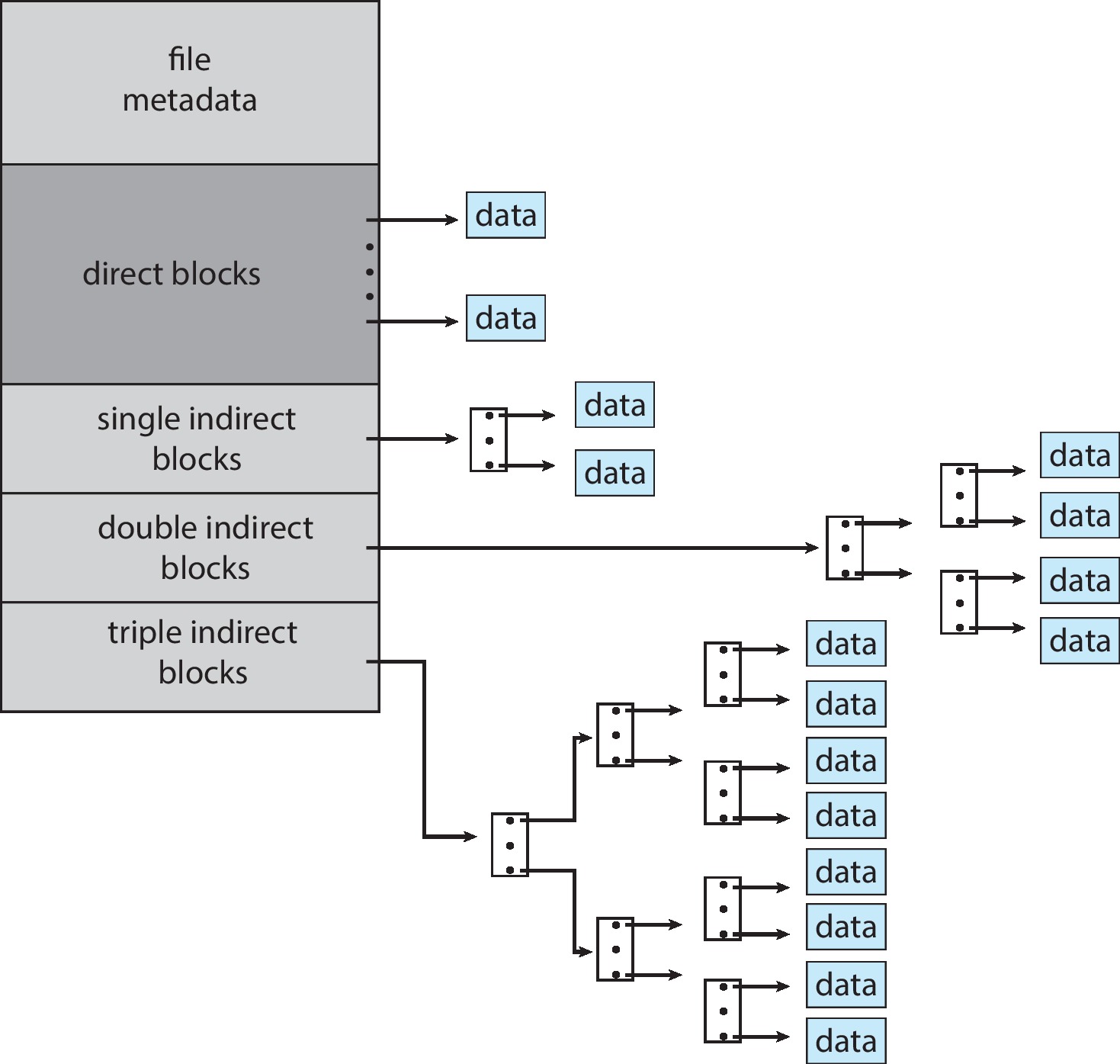
Figure 14.8: The unix inode - Indexed allocation
utilizes a per-file table
where all the physical addresses of the data blocks of the
file are stored.
-
14.4.4 Performance
- Linked allocation is appropriate for files that will be accessed sequentially, but not for files to be accessed directly.
- Contiguous allocation performs well supporting both direct access and sequential access, but not increasing the size of a file, nor controlling external fragmentation.
- The performance of indexed allocation depends on implementation details - usually it is somewhat better than the performance of linked allocation, but not as fast as contiguous allocation.
- Some systems use more than one allocation method and try to match the allocation method to the size of files and/or the ways that the files are used.
- Different algorithms and optimizations are needed for nonvolatile memory (NVM) devices that don't have moving parts.
- Some sort of data structure is required to keep track of
which file blocks are allocated, and which are free.
-
14.5.1 Bit Vector
- A bit map or bit vector is a sequence of bits.
the ith bit represents the ith physical block.
If the ith physical block is free, the ith bit in the vector
is 1, else it is 0.
- It is simple to implement bit vectors and devise algorithms
for locating free blocks and runs of contiguous free blocks.
Instructions that might be used: "ISZERO" and bit-shift.
- However, bit vectors are not efficient to use unless they are cached entirely in primary memory. It is fairly common nowadays (the year 2019) for a laptop computer to have a terabyte disk and 16GB of primary memory. If the disk has 4KB blocks or clusters, the bit vector would need about 32 MB of physical memory, which is about 0.2% of the 16GB.
- A bit map or bit vector is a sequence of bits.
the ith bit represents the ith physical block.
If the ith physical block is free, the ith bit in the vector
is 1, else it is 0.
-
14.5.2 Linked List
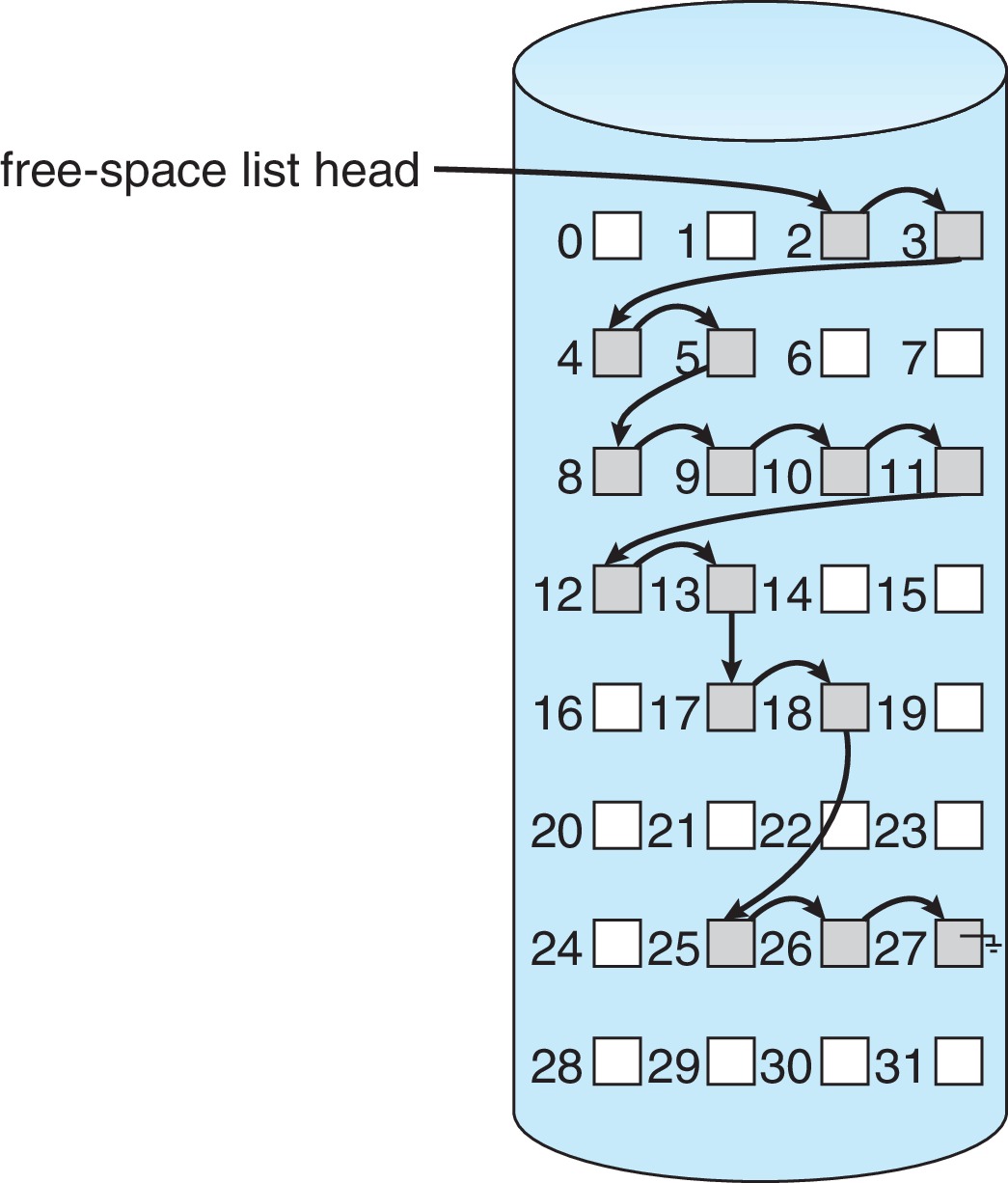
Figure 14.9: Linked free-space list on disk - If contiguous blocks are not needed, then simply storing a link to another free block in each free block is a reasonable approach.
-
14.5.3 Grouping
- In this variant of linking, the first block in the free list structure contains n-1 pointers to free blocks, and finally one pointer to another block like itself, which points to n-1 more free blocks and another block like itself, and so on.
- This structure makes it possible to find a large number of free blocks quickly.
-
14.5.4 Counting
- Make a list of contiguous runs of free blocks by storing pairs of the form (base address, # of blocks)
- The list will be compact if most runs are longer than 1 block.
- Store these records in a balanced tree for efficient search, insertion, and deletion.
-
14.5.5 Space Maps
- ZFS uses a scheme that divides the volume into areas with separate free lists.
- ZFS logs allocation and freeing activity and then uses the log to update in-memory copies of free lists with batches of changes.
-
14.5.6 TRIMing Unused Blocks
- Unlike HDDs, NVM flash-based storage devices require that freed space be erased in units of blocks composed of pages before it is possible to rewrite the media. Erasure can take a relatively long time.
- There's a need for a mechanism by which the file system can inform the storage device when all the pages in a block are free, which is the point at which erasure of the block may begin. For ATA-attached drives the mechanism is TRIM, and for NVMe-based storage, there is an unallocate command. This keeps storage space available for writing.
This section discusses ways to improve the efficiency and performance of secondary storage.
-
14.6.1 Efficiency
- A unix optimization is to spread inodes out across the filesystem
and to try to locate the data blocks of each file close
to the file's inode. The aim is to reduce the seek times
when filesystem operation consult the inode to locate a data block,
and access the data block immediately afterwards.
- Also unix uses variably sized clusters to lessen internal
fragmentation. Larger clusters are for larger files.
Smaller clusters are for small files or the last cluster of a file.
- "Generally, every data item associated with a file needs to be considered for its effect on efficiency and performance."
- A unix optimization is to spread inodes out across the filesystem
and to try to locate the data blocks of each file close
to the file's inode. The aim is to reduce the seek times
when filesystem operation consult the inode to locate a data block,
and access the data block immediately afterwards.
-
14.6.2 Performance
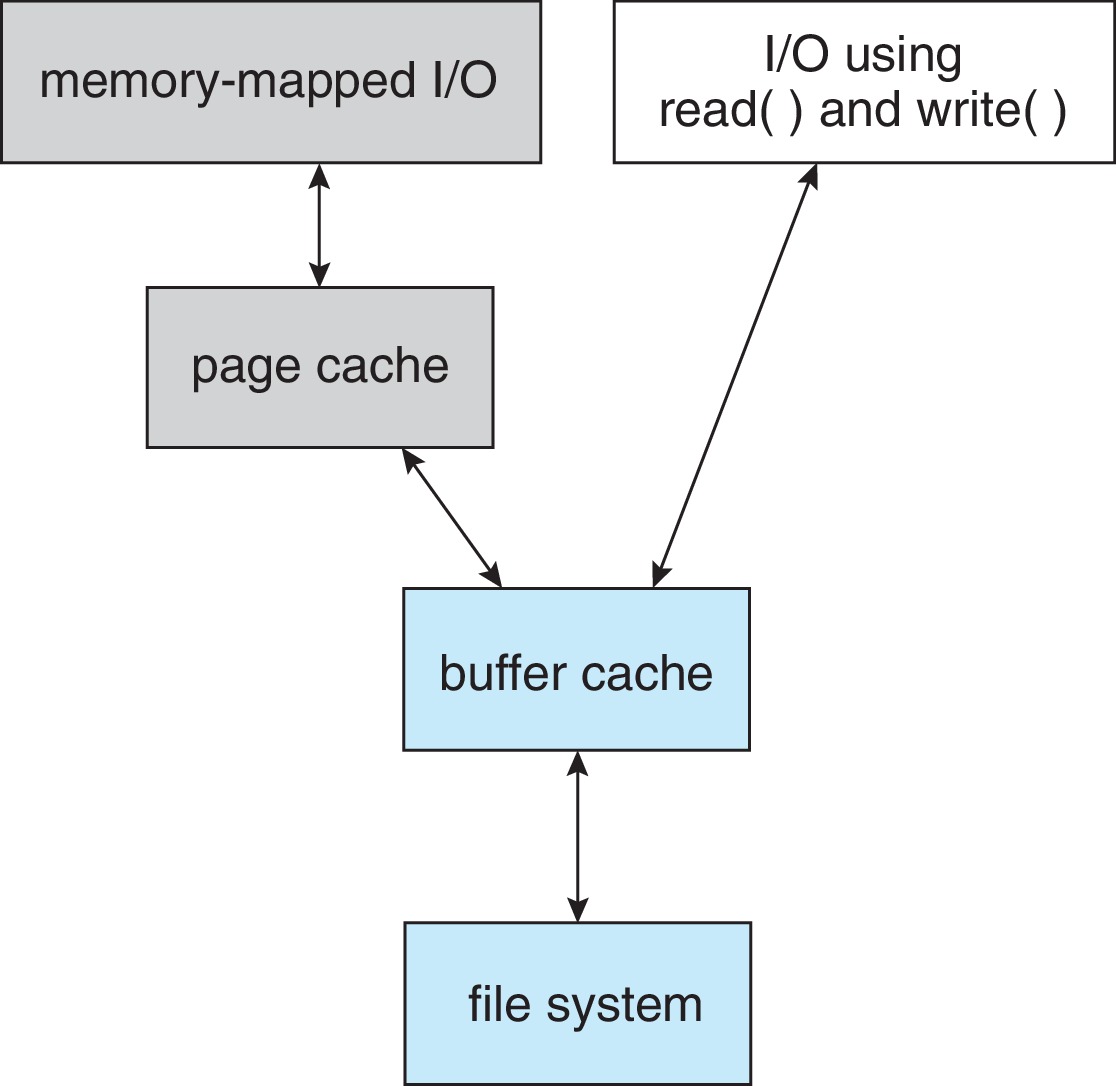
Figure 14.10: I/O without a unified buffer cache 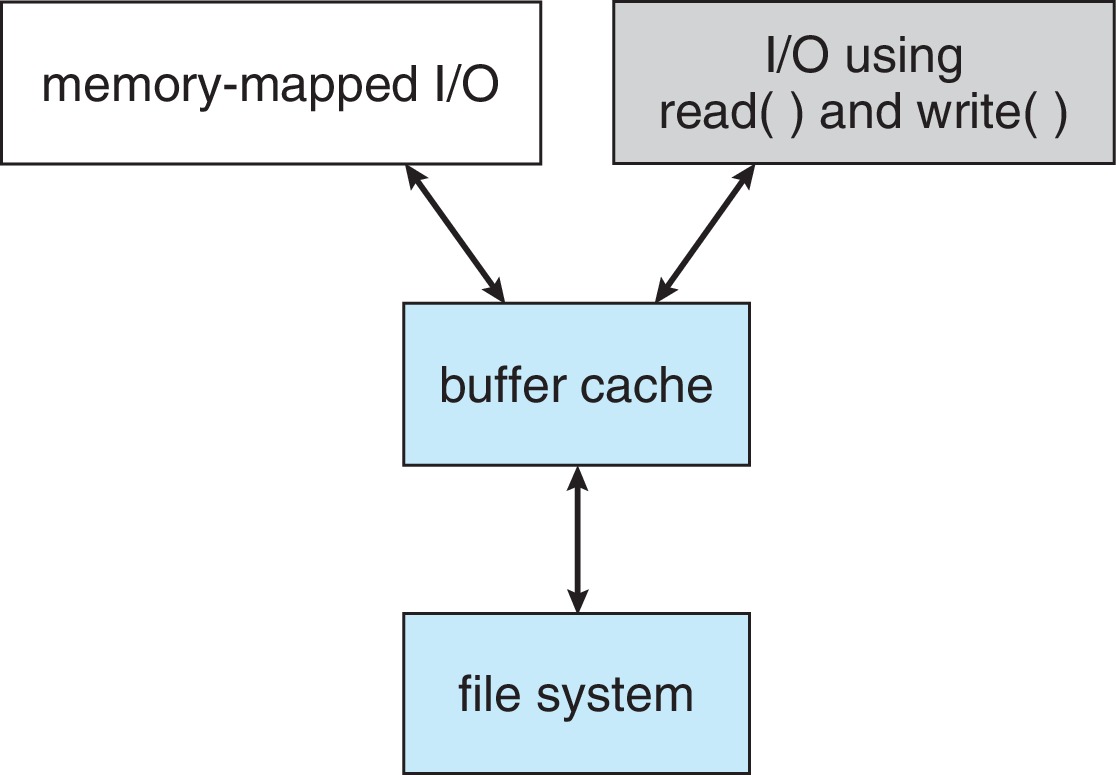
Figure 14.11: I/O using a unified buffer cache - A unified buffer cache (process pages and file data)
enhances performance, using virtual memory techniques,
and avoiding double-caching.
- Frame allocation must be balanced so that processes
can't take away too many frames that are needed for
file caching, or vice-versa.
- When writes to file blocks are synchronous, processes must
wait for data to be flushed to secondary storage before
continuing.
- On the other hand, when processes write asynchronously,
delays tend to be short - often significantly shorter
than delays for reads, since the OS can return control
to the process immediately after caching the write data
in primary memory.
- When a file is accessed sequentially it is often a good
idea to use free-behind
and read-ahead.
- Free-behind: After page buffers are accessed, they
should be freed almost immediately
because they will probably not be accessed again. This is
contrary to LRU, but makes sense in this context.
- Read-ahead: Similarly, when reading a block into buffers from a file which is being accessed sequentially, several of the blocks that follow in the file should also be brought in from disk because they will probably be accessed very soon and it saves on disk access time to batch them this way.
- A unified buffer cache (process pages and file data)
enhances performance, using virtual memory techniques,
and avoiding double-caching.
-
A crash or other failure can interrupt the OS while it is making
changes to metadata, which can leave a file system in a damaged
and/or inconsistent state. Such damage can also occur if the OS
crashes before it is able to flush cached metadata changes to
non-volatile secondary storage. Other things, such as bugs in
software and hardware, can result in damage to a filesystem.
The OS must take measures to protect the system from loss of data and to recover from failures.
-
14.7.1 Consistency Checking
- The OS may utilize a consistency checker
such as the unix fsck to resolve
inconsistencies between
the directory structure and the data blocks.
- Details of the file system implementation, such as
the allocation algorithm and free-space management
algorithm, determine what kinds of problems a consistency
checker can detect and correct.
- For example, if there is linked allocation, a file can be reconstructed from its data blocks.
- The OS may utilize a consistency checker
such as the unix fsck to resolve
inconsistencies between
the directory structure and the data blocks.
-
14.7.2 Log-Structured File Systems
- The use of log-based recovery algorithms has become
common, enhancing protection of file systems.
-
The basic idea is to write changes to metadata to a log
first, and then replay the log entries across the
actual file system metadata structures that need to be
changed.
- If the system crashes, the OS can use the log to resolve any inconsistencies during a recovery phase.
- The use of log-based recovery algorithms has become
common, enhancing protection of file systems.
-
14.7.3 Other Solutions
-
WAFL and ZFS file systems never overwrite blocks with
new data.
-
Changes are written to new blocks and then pointers
to old blocks are updated to point to new blocks.
-
Old pointers and blocks may be saved in order to provide
snapshots of previous states of the file system.
- ZFS employs checksums for all metadata and file blocks, further reducing chances of inconsistency.
-
WAFL and ZFS file systems never overwrite blocks with
new data.
-
14.7.4 Backup and Restore
- Backup schedules involve some combination/rotation of
full and incremental backups.
- Some backups should be saved "forever," in case a user
discovers a file was damaged or deleted long ago.
- Protect backup media by storing it where it will be safe,
and
make sure to always have backups on media that
is in good condition, and not worn out.
- Verify the condition of backups on a careful schedule.
- It's a good idea to have backups at more than one site, in case something unexpected happens to render one set of backups unusable.
- Backup schedules involve some combination/rotation of
full and incremental backups.
- The Write Anywhere File Layout (WAFL) file system is optimized
for random writes, and designed for servers exporting files
under the Network File System (NFS) or Common Internet File System
(CIFS).
- WAFL is similar to the Berkely Fast File system, but with many
differences.
- All metadata is stored in ordinary files.
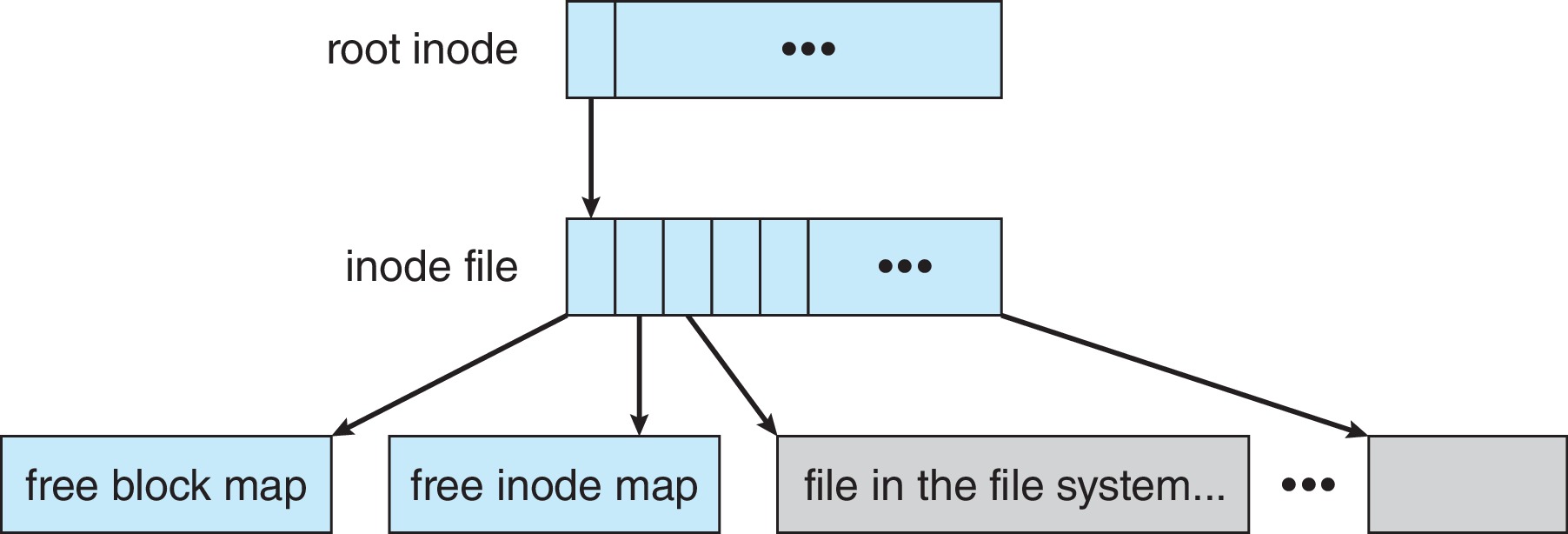
Figure 14.12: The WAFL file layout - WAFL never writes over blocks, and can provide snapshots of
previous states of the files system using copies of old root nodes.
Going forward the changes in the file system are recorded in copy-on-write
fashion.
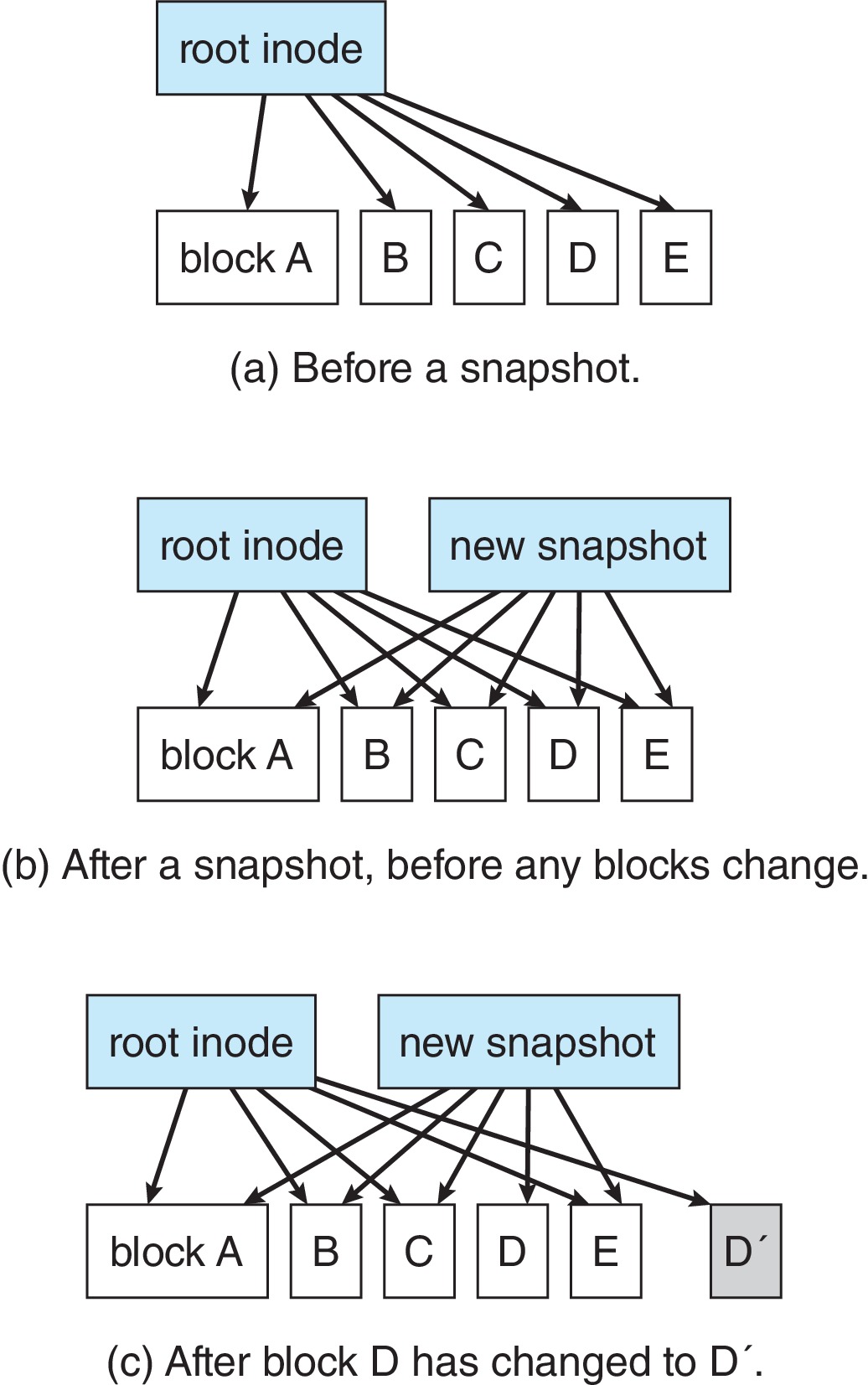
Figure 14.13: Snapshots in WAFL - Writes can always occur at the free block nearest the current head location.