(Latest Revision: Thu Jun 06 2019)
[2019/06/06: added some figures]
[2019/06/06: added captions]
[2019/05/07: completion of first full version for 10th edition]
The implementation of file systems is a major aspect of operating
system architecture. Designers have to decide how to map
file system information onto the physical storage device(s), and what
methods to provide for access and manipulation. File systems are
often performance bottlenecks, and it is quite a challenge to make
them adequately efficient.
File systems consist of two parts, a collection of files and a directory
structure. The purpose of the directory structure is to provide
information about, and organization of the files.
13.0 Objectives
Explain the function of file systems.
Describe the interfaces to file systems.
Discuss file-system design tradeoffs, including access methods,
file-sharing, file locking, and directory structures.
Explore file-system protection.
13.1 File ConceptA clinking, clanking, clattering collection of caliginous junk
A file is a logical unit of storage -
the smallest allotment of logical secondary storage,
a named collection of related information that is recorded
on secondary storage, "a clinking, clanking, clattering collection
of caliginous junk," as it were.
13.1.1 File Attributes
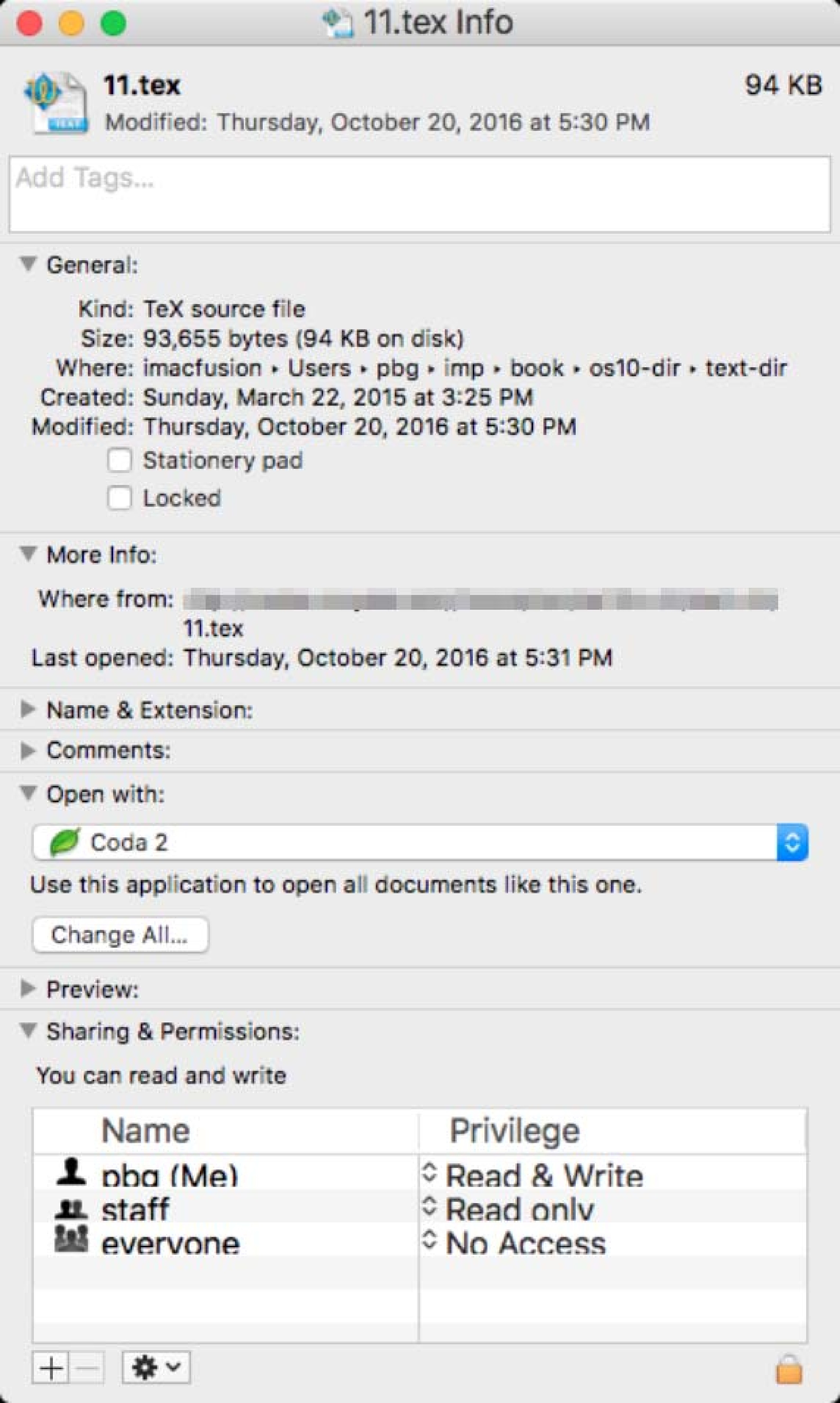
Figure 13.1: A file info window on MacOS
Typical file attributes include
Name (human readable)
Identifier (unique id number)
Type (info needed for OS support of file type)
Location (a pointer to the file's location on a device)
Size (number of, say, bytes, words, or blocks)
Protection (indication of who or what has permission
to read, write, execute, and so on)
Timestamps and user identification (things like time
and date of creation, last modification, or last use)
There are many other possibilities for attributes, such as
the character-coding used for a text file, or a file checksum.
An operating system stores file attributes in the
file-system directory structure.
13.1.2 File Operations
Files are abstract data structures. They have associated
file operations, which are implemented with system calls:
Creating a file (allocate space and make entry in a directory)
Opening a file (cache info about the file in main memory and
return a pointer to it)
Writing a file (may involve updating a pointer
to current file position)
Reading a file (also may involve updating a pointer
to current file position)
Repositioning within a file
(change the value of the file pointer)
Deleting a file (remove entry from directory
and deallocate space no longer used)
Truncating a file (release space and reset size to zero)
The operations above are a minimal set. Designers can implement
other operations using combinations. For example to copy a file
we can create a new file, then read from the old and write to the
new.
Many systems require that files be opened before use.
The open operation places directory information about
the file into an open file table data structure in
primary memory. That way, processes will be able to
make a lot of accesses to the file without needing to
fetch directory information from the disk each time.
In systems that allow multiple processes to have a file open
simultaneously,
it is customary to have two levels of open file tables
- a single system-wide table, and multiple
per-process open file tables. Each per-process table holds information
having to do with the particular process' use of the file,
such as the current read and write positions of the process
in the file. The entry for a file in the per-process table
contains a pointer to the entry for the file in the
system-wide table.
Process-independent things like location of the
file on disk, access dates, file size, and file open
count are contained in
the file's entry in the system-wide file table.
Info associated with an open file:
File pointer (last read/write location of the process)
File-open count (number of processes that have the file open)
Location of the file (to locate where to read/write)
Access rights (the mode of file use granted to the process)
File-locking operations may be available, shared
and/or exclusive locks, mandatory and/or
advisory locks.
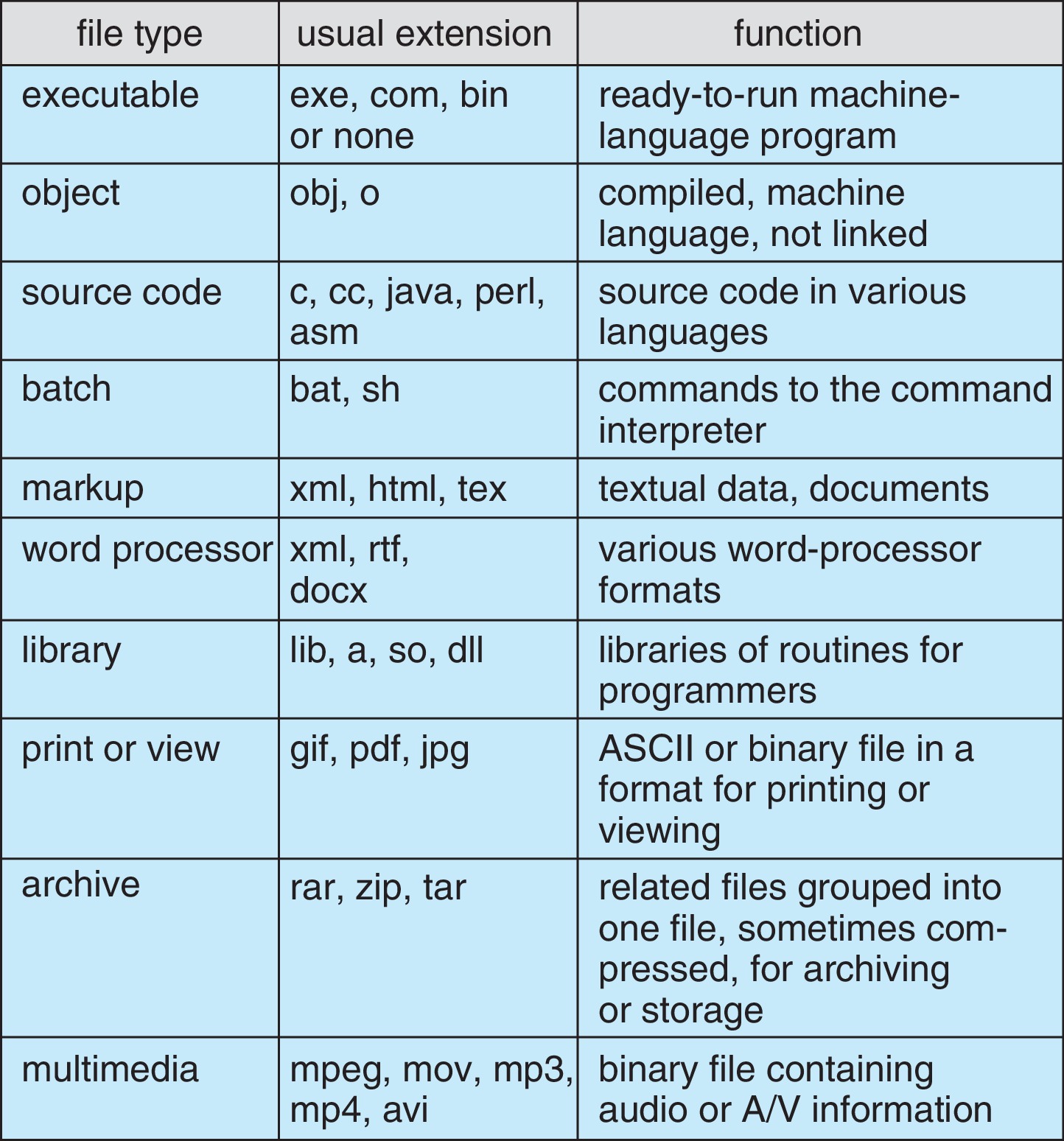
13.1.3 File Types
There are various file types, such as text, binary,
executable. Often filename extensions are used to indicate
the type of a file. Most file types are not fully supported
by the operating system.
It is common for the OS to treat most files simply as an
unstructured sequence of bytes.
13.1.4 File Structure
Each OS must fully support at least one executable file type,
so that the OS can load and execute programs.
Figure 13.3: Common file types
13.1.5 Internal File Structure
All basic I/O functions are performed block by block -
physical file blocks - normally the 512-byte data sections
of disk sectors.
Files are sequences of logical records that must be mapped
to file blocks. Applications may do the mapping, or the
OS may do it.
All files are allocated in whole numbers of physical blocks,
and therefore
all file systems suffer from internal fragmentation.
13.2 Access Methods
Information in files can be accessed in different ways.
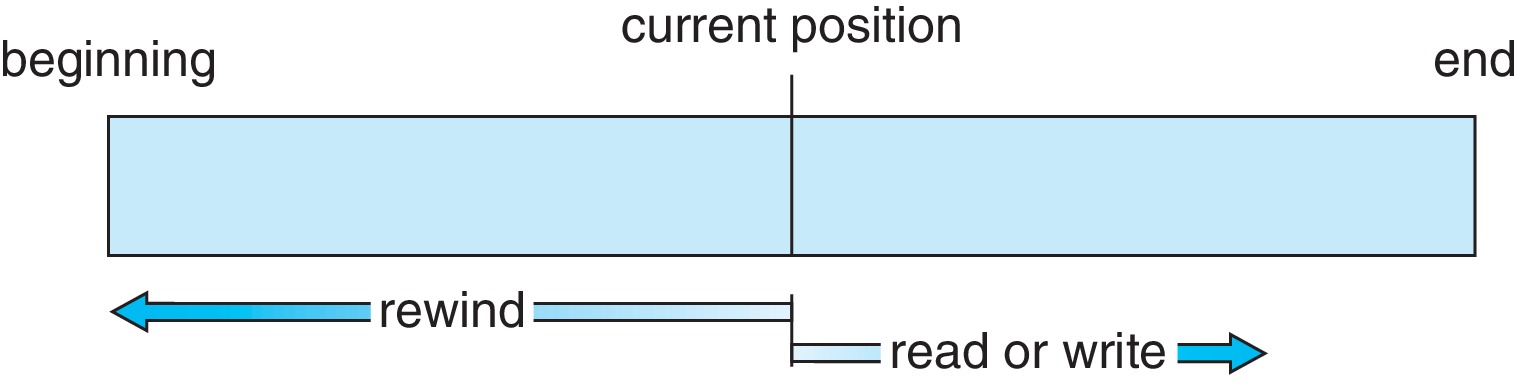
13.2.1 Sequential Access
Sequential access is the simplest and most
common file access method.
The file is read as a sequence from start to finish,
as a tape would be read.
Writing is similar. Each write operation appends
a new item to the end of the file.
"Read next" and "write next" are typical operations.
The OS maintains a pointer to the current location in the file.
The OS may support an operation to reposition the pointer (seek).
Figure 13.4: Sequential-access file
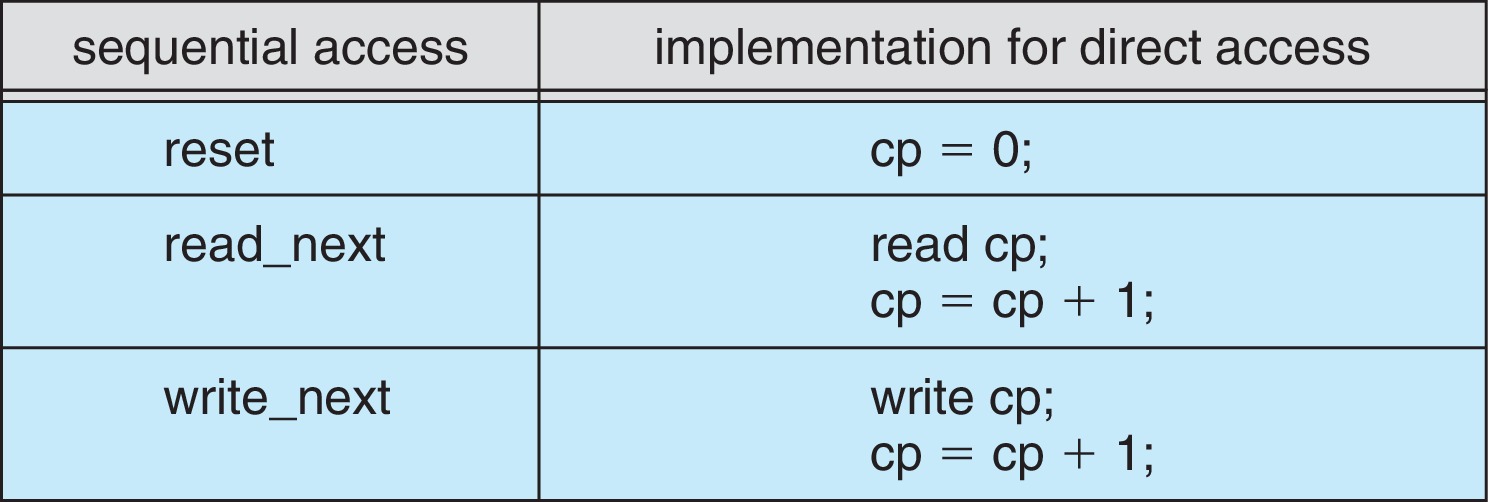
13.2.2 Direct Access
Direct access allows the user to access blocks in arbitrary order
- to treat the file as if it
were an array of file blocks.
Typical operations are of the form read block #n or
write block #m.
Block numbers are usually logical addresses that run
from 0 contiguously to some upper limit.
Assume that the first byte in the file is numbered 0,
that the file is a sequence of records of size L bytes,
that the records are numbered starting at 0,
and that we want to request the Nth record in the file.
In that case we compute the starting byte number N*L
and fetch the L bytes of the file starting with byte N*L.
Figure 13.5: Simulation of sequential access on a direct-access file
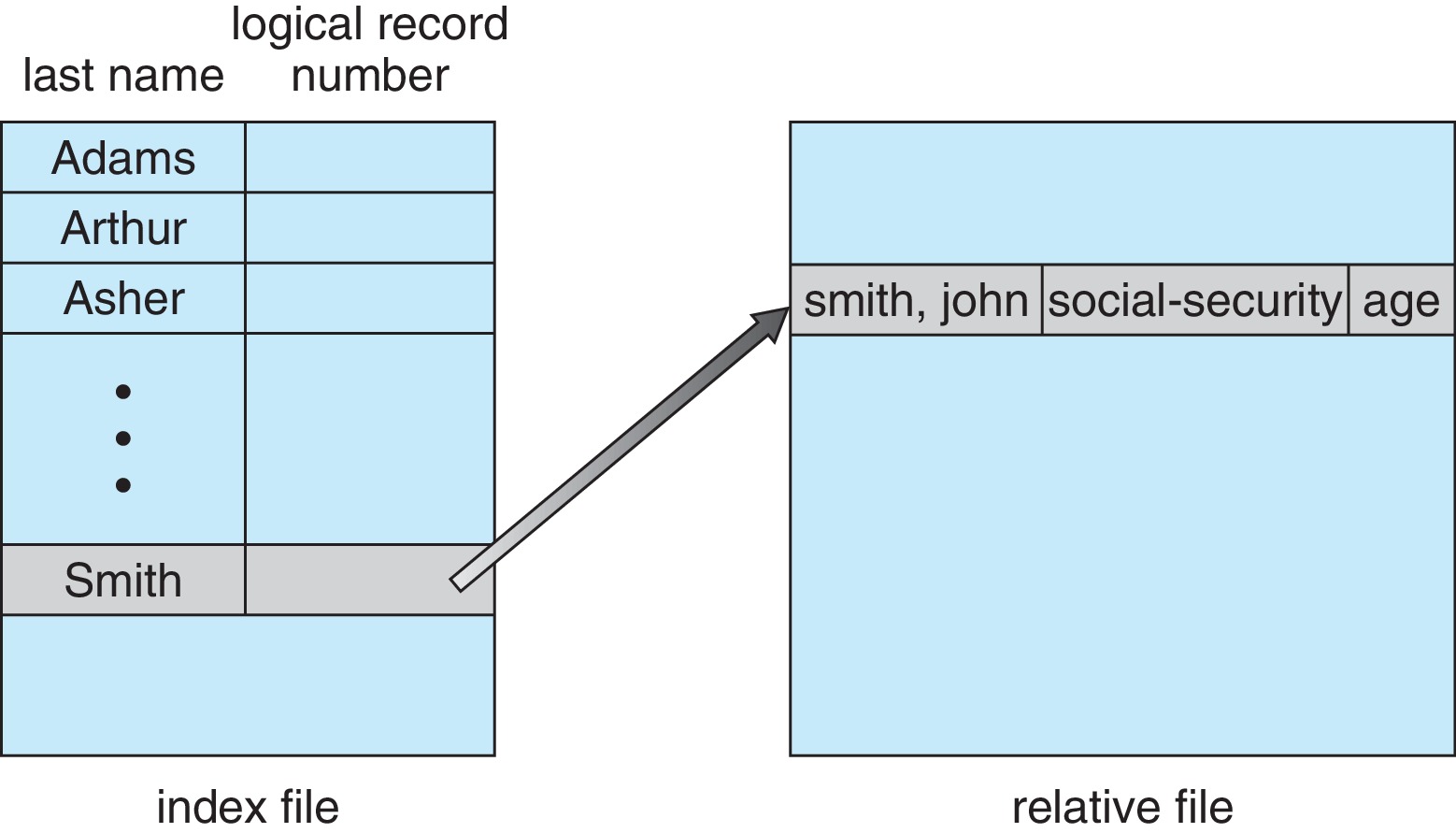
13.2.3 Other Access Methods
Other access methods can be built on direct access, often
using an index to look up file block numbers and
then using direct access.
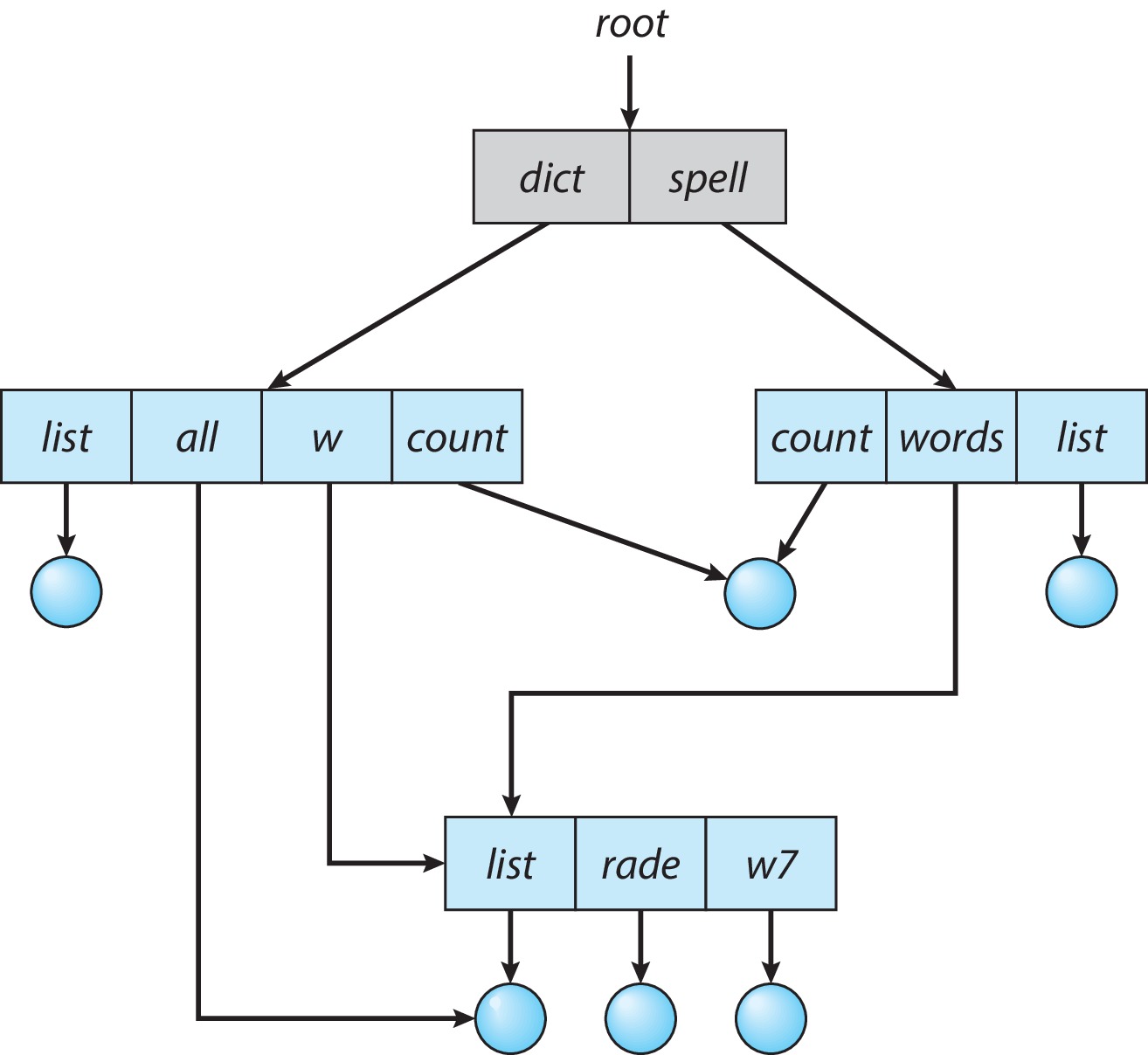
Figure 13.6: Example of index and relative files
13.3 Directory Structure
The directory is basically a table for looking up
information about files, using the name of the file
as the lookup key.
The directory structure needs to support the following operations.
Search for a file (by name)
Create a file (add to directory)
Delete a file (remove from directory)
List a directory (list names and info for files in directory)
Rename a file (change directory entry)
Traverse the file system (access all directories and files,
for example when performing a backup)
13.3.1 Single-Level Directory
In this scheme the directory works like
a single list of entries.
Even if there are multiple users, no two
files are allowed to have the same name.
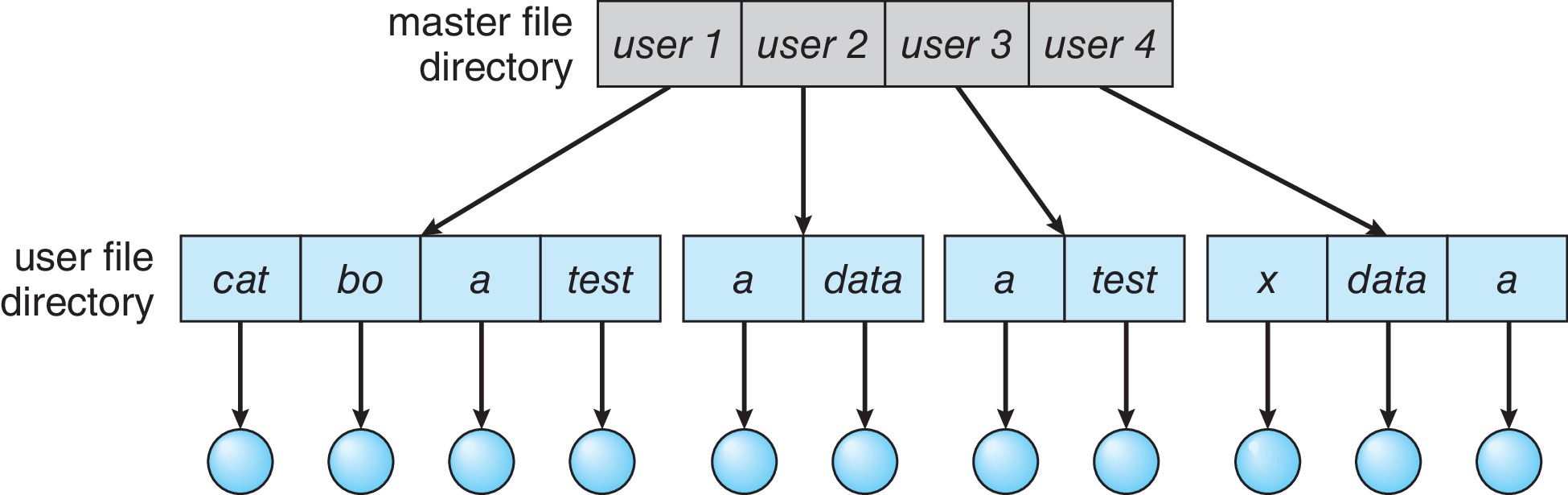
In a two-level directory structure,
there is a
master file directory that has multiple sub-directories.
Each user on a computing system can be assigned his or her
own 'home' directory. Users can name files whatever
they like without fear of collisions with the filenames
of other users.
If a user name and file name within the user's directory are
specified, this "pathname" uniquely determines which file it is.
The OS assumes that a filename without a user name refers to the
user's own directory, or to a special directory that contains
the system files (e.g. programs that are user shell
commands)
The sequence of directories searched when a file is named is
called a search path.
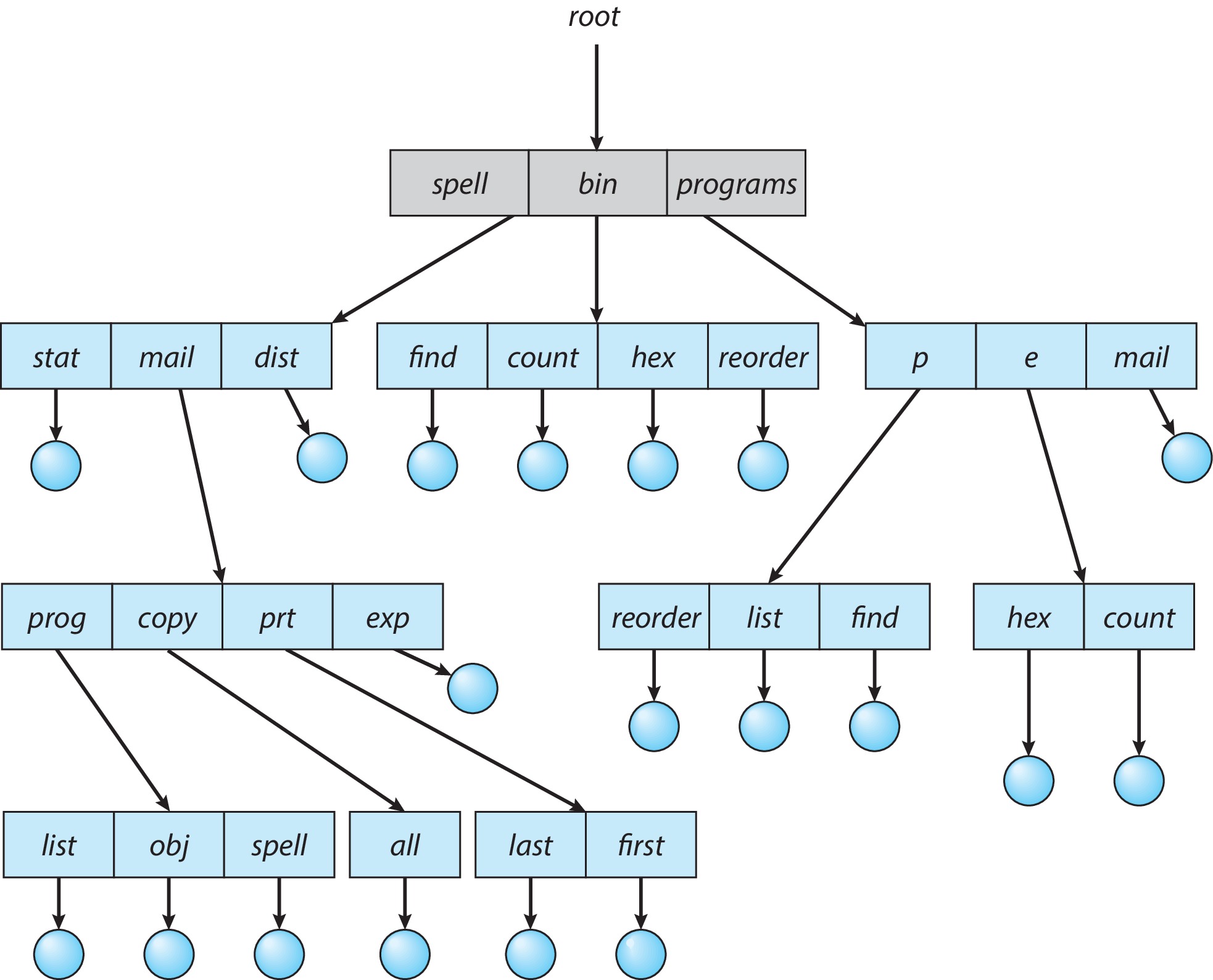
The tree-structured directory is a generalization of the
two-level directory structure that allows users to create
their own tree of subdirectories, and to use this structure
to group and organize their files.
The tree has a root, and every file or directory has a unique
pathname that starts with the root.
Processes can typically "move around" in the tree, by
using a system call to specify which directory is their
current working directory.
The accounting file (e.g. passwd file) of a user
typically designates which directory should initially
be made the current working directory when the user
logs in.
Pathnames can be absolute or relative.
How to delete directories is an interesting policy decision.
This structure allows directories to share a file
or subdirectory. By definition, this is not possible
in a tree.
Shared files and subdirectories may be implemented
through the use of (symbolic) links
[aka soft links]. A symbolic link
may be thought of as a file that contains a path name.
The directory entry of the symbolic link has
a special bit value set that marks the file as
a link rather than an ordinary file. For example,
if /x/y is a file that we wish to share, we can
put a symbolic link in /z containing the pathname
"/x/y" and name the symbolic link (file) r.
Then all references to /z/r
will access the same file as /x/y.
Going on with the previous example, the original
directory entry for /x/y is sometimes referred to
as a hard link. It is just an ordinary
directory entry, typically consisting of the name
of the file (y, in this case) and the address on disk of the
directory information for the file.
Another way to implement the sharing of the file
would be to use another hard link - an entry in the
/z directory that contains the other name
(r, in this case), plus the same address
on disk of the directory information
for the original file (known as /x/y). This gives us
two separate directory entries that point to the
same file on disk.
When there are multiple hard and/or soft links to files
and/or directories, designers of the system must take
care when implementing the file and directory deletion
operations. Pointers can be left dangling and/or file
space can be deallocated when the files are still in use.
13.3.5 General Graph Directory
In a general graph directory structure,
cycles of directories are allowed to exist.
When such cycles are possible, it is more difficult
to design algorithms that search and traverse the file system
correctly. It is also more difficult to find and deallocate
some directories that are no longer connected to the main part
of the file system.
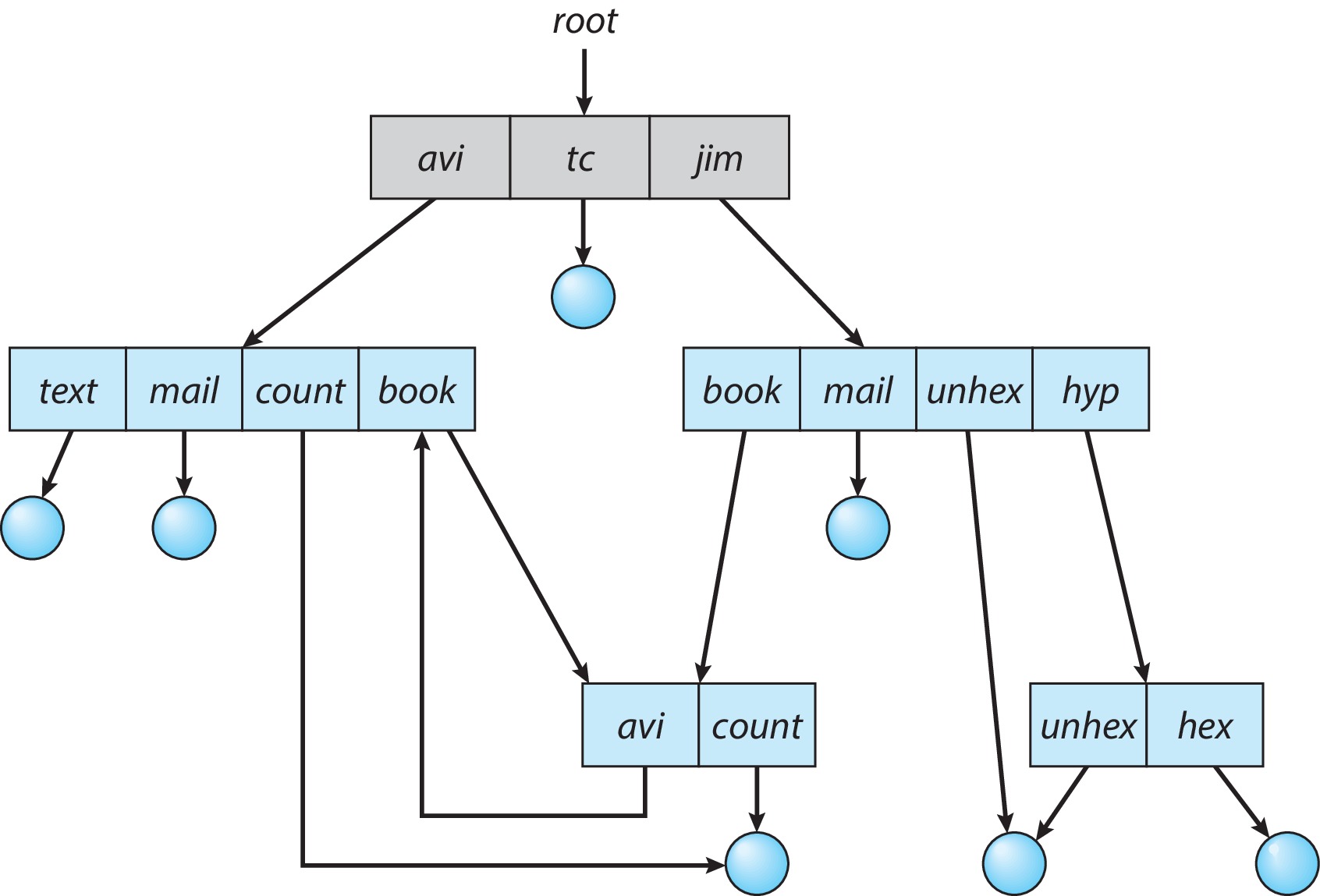
Figure 13.11: General graph directory
13.4 Protection
When valuable information is stored on a computing system we
want to keep it safe from physical damage and improper access.
13.4.1 Types of Access
We have to provide access to files, but we need controlled
access.
Here are examples of operations that must be controlled:
Read (from file)
Write (to file)
Execute (load and execute file)
Append (add info to end of file)
Delete (delete the file and free its space)
List (list the name and attributes)
Attribute change (change file attributes)
There are different kinds of protection mechanisms, suited to
different sorts of computing systems. The next few sections
discuss a few aspects of protection. There's more detail in
Chapter 20.
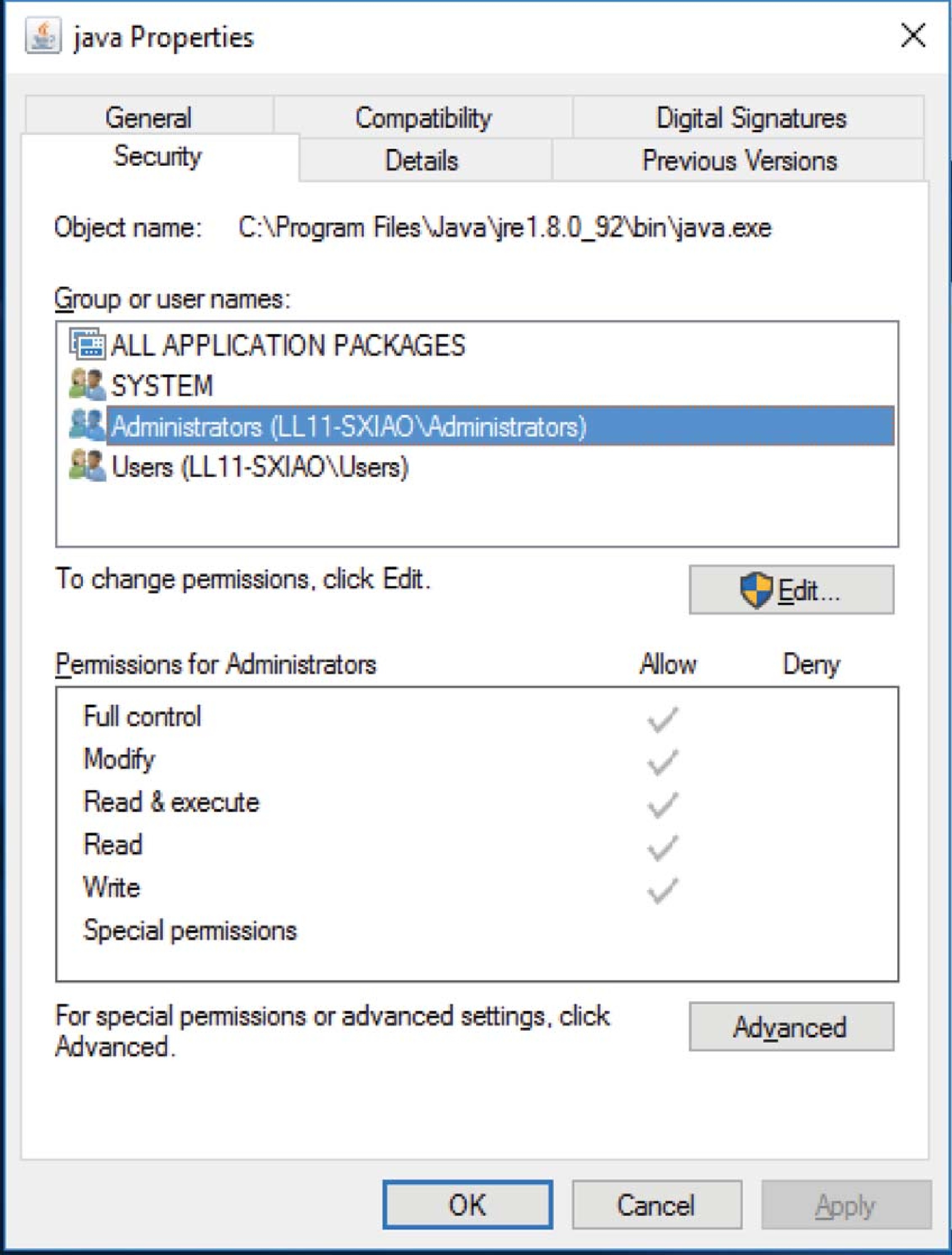
Figure 13.12: Windows 10 access-control list management
13.4.2 Access Control
One approach to controlling access to files would be
to keep an access control list (ACL) with each file
or directory. The ACL is a table data structure keyed
on user id. Given the id of any user, one can look up
the specific access rights the user has on the file
or directory object. It's difficult to implement such
full ACLs.
Many systems are designed with a condensed form of ACLs
in which access rights are stored just for three entities:
the owner of the file (or directory), the group,
and everybody else.
Owner (the owner is the user who created the file)
Group (a designated 'work group')
Other (everyone else who uses the system)
Some systems, like Solaris, use the (owner, group, others)
approach by default, but also allow more detailed access
controls to be added to specific file objects. (The term file
object is meant to include files, directories, and other
special kinds of items that might exist in the file system.)
Read, write, and execute bits are commonly associated with
each of the three classes: owner (user), group, and other.
For a plain file, a set read bit means a member of the class
has permission to read the file. Similarly the write bit gives
permission to write, and the execute bit gives permission
to execute the file (presumably the file is a program,
script, or the like).
For directories, the read bit gives permission
to list the directory. The write bit allows creation
of new files in the directory and, if it is empty,
deletion of the directory. The execute bit gives permission
to cd to the directory, and to access the file objects in the
directory, subject to the permissions on the objects
themselves.
Users who lack either write or execute permission
on a directory cannot delete a file object in that
directory.
13.4.3 Other Protection Approaches
One approach is to assign a password to a file or
directory.
It can be complicated to manage multiple passwords
on multiple objects.
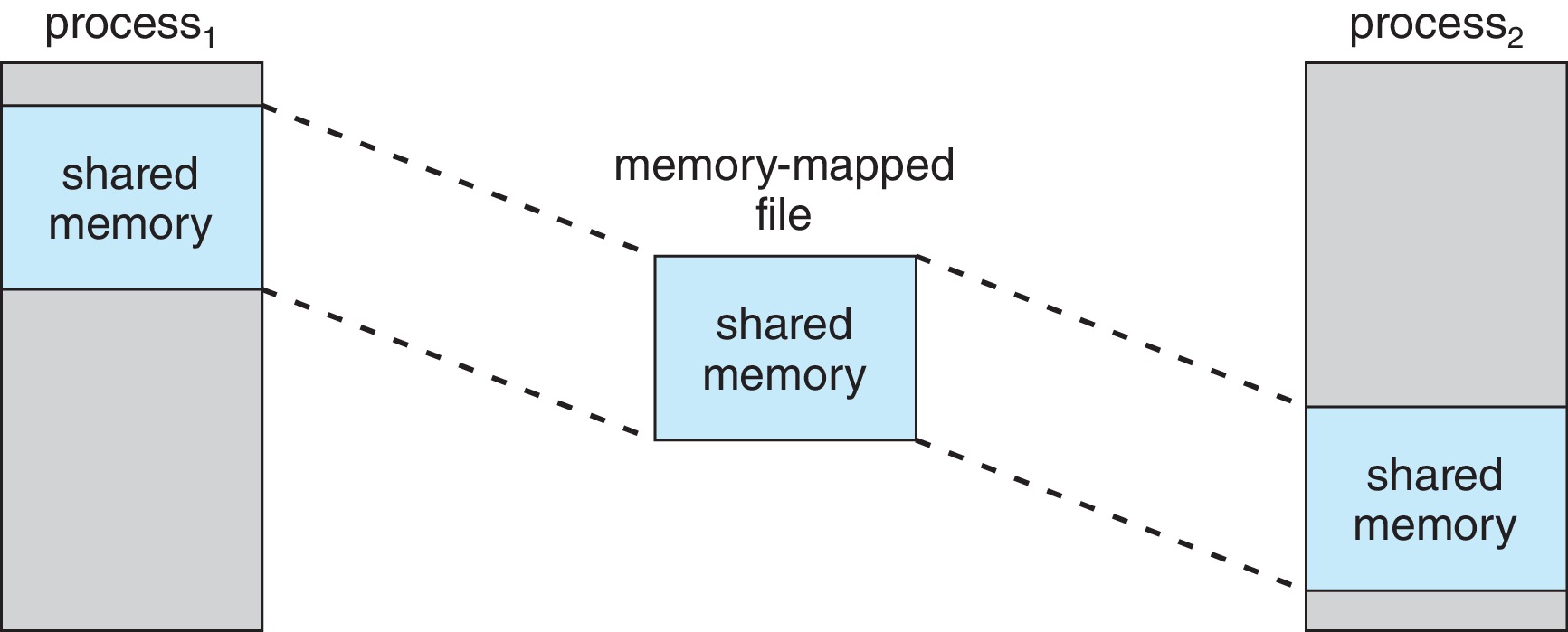
13.5 Memory-Mapped Files
File I/O sometimes requires multiple time-consuming system calls
and disk accesses. Designers can make things more efficient
with virtual-memory techniques.
13.5.1 Basic Mechanism
The system can handle the initial accesses to file blocks
just like a page fault. After the OS loads file blocks into
frames of physical memory, the process can access them by using
routine memory-access operations.
The OS can copy modified file blocks through to disk after the
process closes the file, or possibly as part of a periodic
interrupt routine.
When memory-mapping of files is available, it can be used to
implement the sharing of a file by a group of processes, shared
memory, and copy-on-write functionality.
Figure 13.13: Memory-mapped files
13.5.2 Shared Memory in the Windows APIFigure 13.14: Shared memory using memory-mapped I/O