- A virtual memory (VM) system can execute a process that is not completely
resident in main memory.
- Processes can be larger than physical memory.
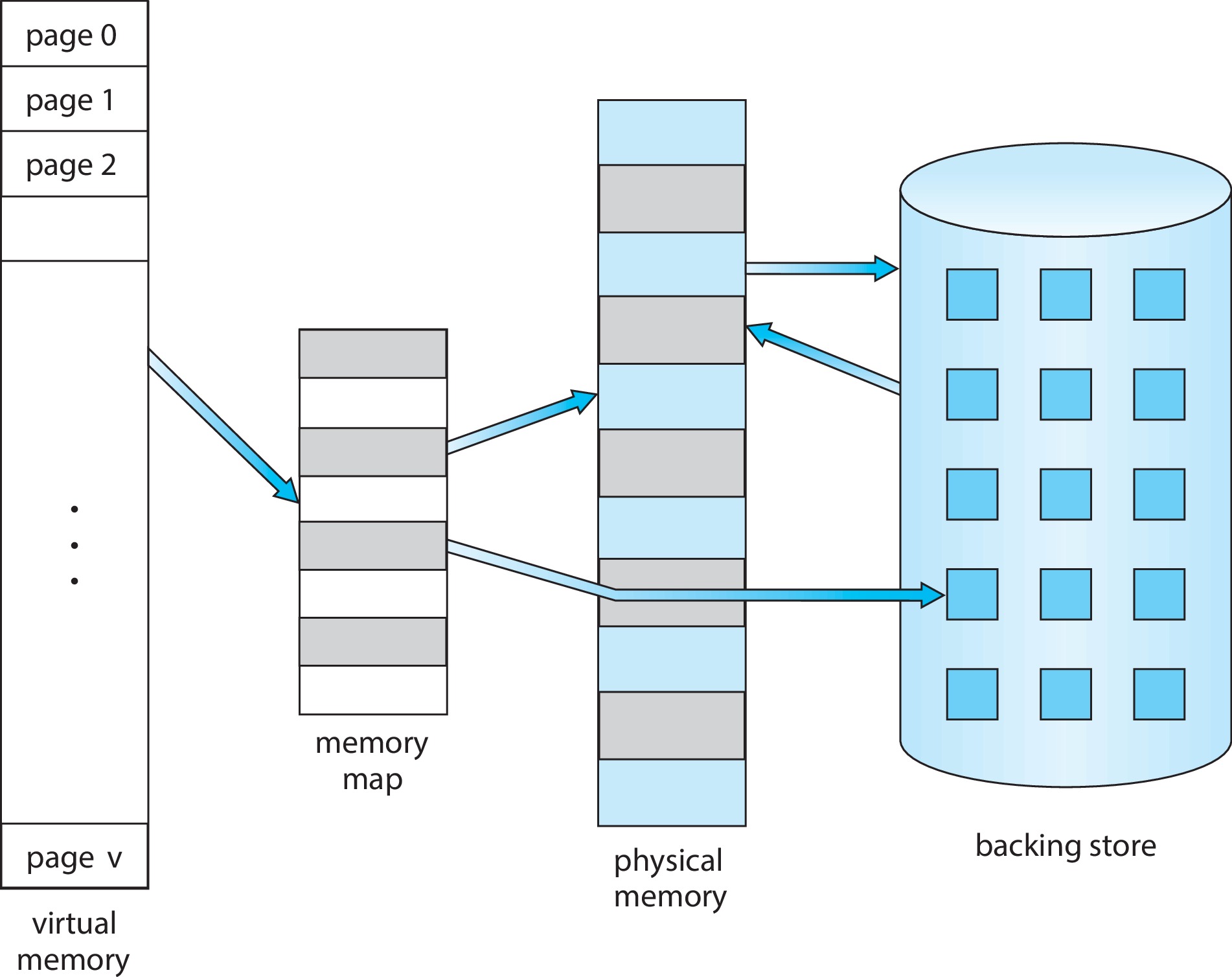
Figure 10.1: Diagram showing virtual memory that is larger than physical memory - Systems can use VM techniques to make process creation
efficient, and to allow processes to share files, libraries, and
memory.
- VM can very significantly degrade performance if not implemented with care, or not used with care.
- Define virtual memory (VM) and describe its benefits.
- Illustrate how pages are loaded into memory using demand paging.
- Apply the FIFO, optimal, and LRU page-replacement algorithms.
(The course goal is to examine the characteristics of these algorithms.)
- Describe the working set of a process, and explain how it is related to
program locality.
- Describe how Linux, Windows 10, and Solaris manage virtual memory.
- Design a virtual memory manager simulation in the C programming language.
(This is not one of the course goals.)
- Under VM, processes can execute when they are not
fully resident in main memory.
- Potentially, this can mean a higher level of multiprogramming,
higher CPU utilization, greater throughput, and less I/O
for loading and swapping processes.
- Under VM, programmers can be less concerned about how much physical memory is available, because the logical address space is allowed to be (much) larger than the physical memory.
The strategy is to load a page of the process only as needed.
-
10.2.1 Basic Concepts
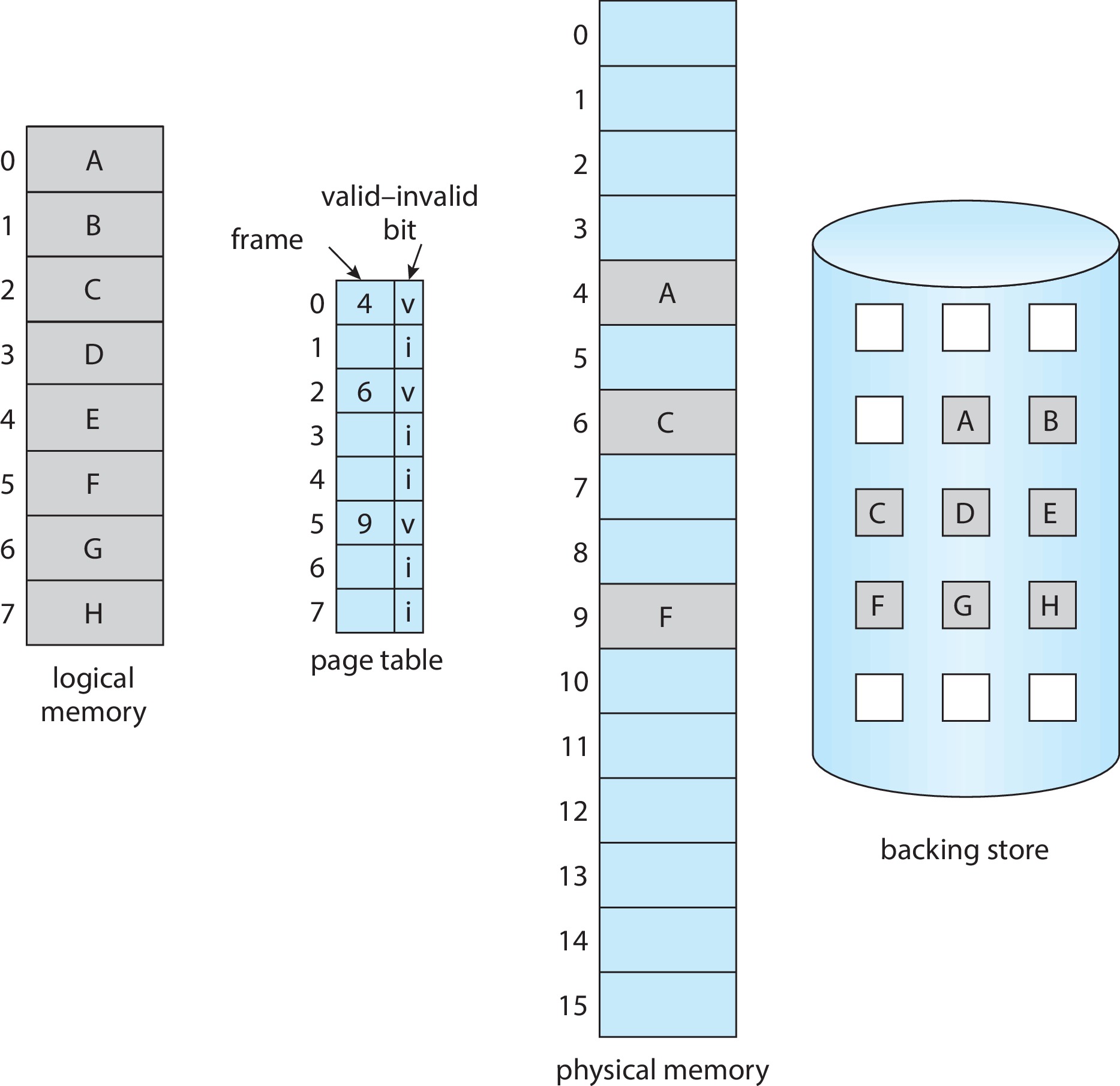
Figure 10.4: Page table when some pages are not in main memory - The OS can mark non-resident pages by clearing the valid bit.
- "Valid" means the page is both legal and resident in main memory.
- "Invalid" means the page is illegal, OR legal but not resident.
- If the process attempts to access a page marked invalid, that will
cause a trap to the OS. The OS will handle the trap by executing
a page fault routine. Here are the steps performed:
- Check internal table to determine whether the page address
is illegal, or legal but not resident.
- If the page is illegal, terminate the process. If legal,
we will copy the page from secondary storage into main
memory.
- Find a free (physical) frame.
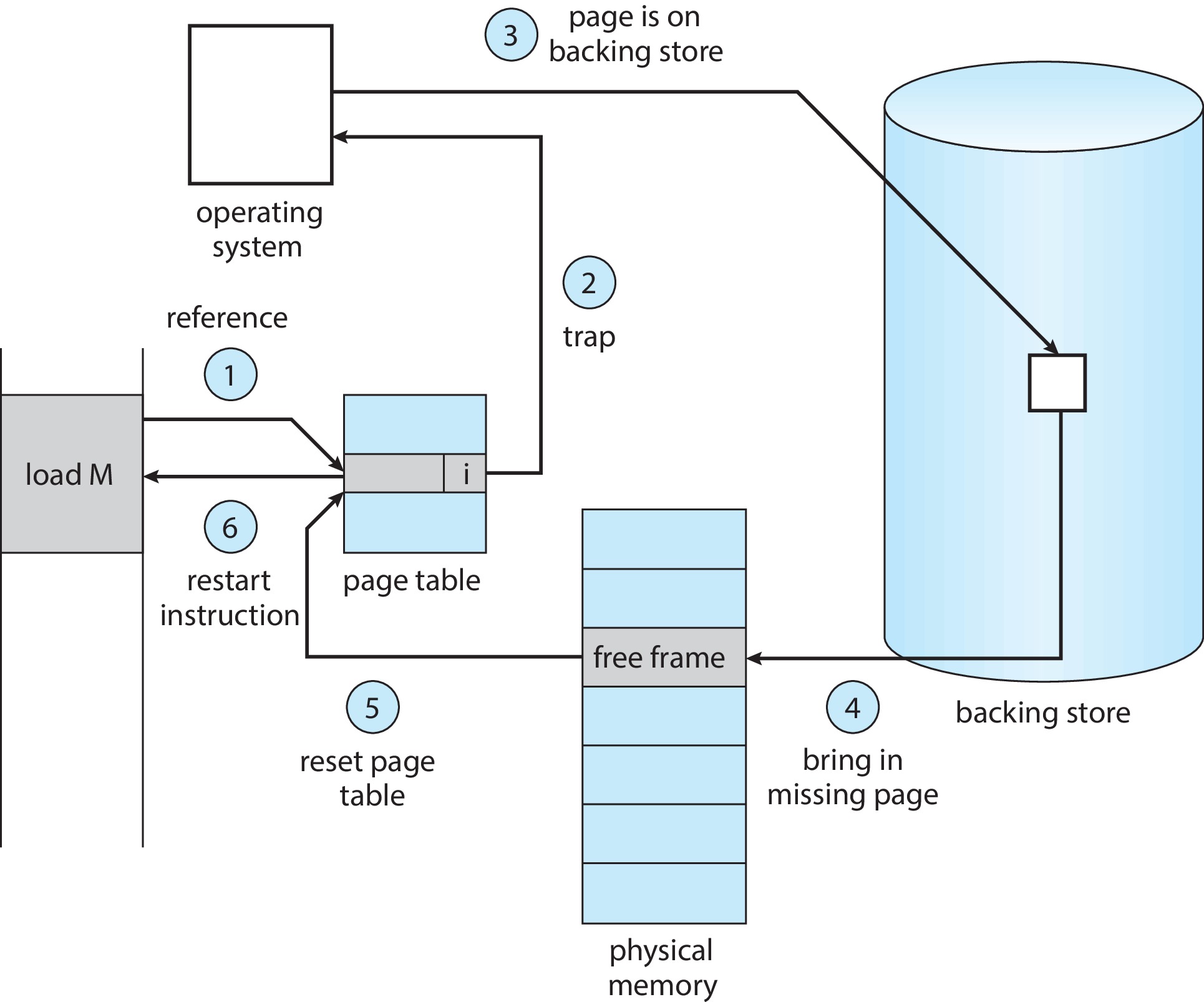
Figure 10.5: Steps in handling a page fault - Schedule a secondary storage I/O operation to read the
desired page into the frame.
- When the I/O op is complete, modify the internal table and
the page table to indicate that the page is now in memory.
- Restart the instruction that was interrupted by the page-fault
trap. Now the process can access the page.
- Check internal table to determine whether the page address
is illegal, or legal but not resident.
- Under pure demand paging, a process begins execution
with no pages in memory. As soon as the process attempts
to fetch its first instruction, it gets a page fault. It continues
to fault until all the pages it needs are in memory.
- Processes normally exhibit locality of reference,
which means that they tend to use relatively small parts of the
code and data for relatively long periods of time, and tend to
shift rather slowly from one area of the code or data to another.
- Due to locality of reference, processes don't tend to get
excessive numbers of page faults under demand paging.
- Hardware needed to support demand paging
(same as for paging and swapping):
- Page table (must have valid bit or other special bits)
- Swap space on secondary memory for storage of pages not resident in main memory
- Instruction architecture in which any instruction can be restarted after a page-fault. (complexities are discussed on pp. 395-396 of the tenth edition.)
- The OS can mark non-resident pages by clearing the valid bit.
-
10.2.2 Free Frame List
- Most OSs maintain a pool of free frames to use when servicing
page faults - a free-frame list.
- Usually, the OS overwrites the previous contents of a frames with zeros before allocating it again. This protects the privacy of the previous user of the frame.
- Most OSs maintain a pool of free frames to use when servicing
page faults - a free-frame list.
-
10.2.3 Performance of Demand Paging
- The
page-fault rate
of a process is the number of
page-faults the process gets during its execution divided by
the number of memory accesses it performs.
- A normal memory access takes somewhere between 10 and 200
nanoseconds.
- If a page-fault occurs during an attempted memory access, it
may require about 8 milliseconds to complete that memory
access, mainly because the page has to be loaded from secondary
storage. It may require additional increments of 8 milliseconds
due to time waiting to reach the 'front' of the device queue.
- there are 40,000 200-nanosecond periods in an 8 millisecond
period. This is like the difference in magnitude between one
second and eleven hours -- eleven hours is about 40,000
seconds.
- Under the assumptions above,
if we get just one page-fault
in every 40,000 page accesses then the effective memory
access time could be double the 200ns figure -- 400ns.
- To assure an effective memory access time below 220ns we would
need to have fewer than one page-fault in every 400,000 memory
accesses.
- The point here is that page-faults can be very
detrimental to effective memory access time and so
it is extremely important to prevent the page-fault rate
from becoming excessive.
- An OS may be designed to limit paging between main memory and the file system, because throughput to swap space is faster.
- The
page-fault rate
of a process is the number of
page-faults the process gets during its execution divided by
the number of memory accesses it performs.
- Windows XP, Linux, and Solaris use copy-on-write with fork().
Instead of copying the entire parent process, the system copies
only the pages on which the parent or child actually
writes.
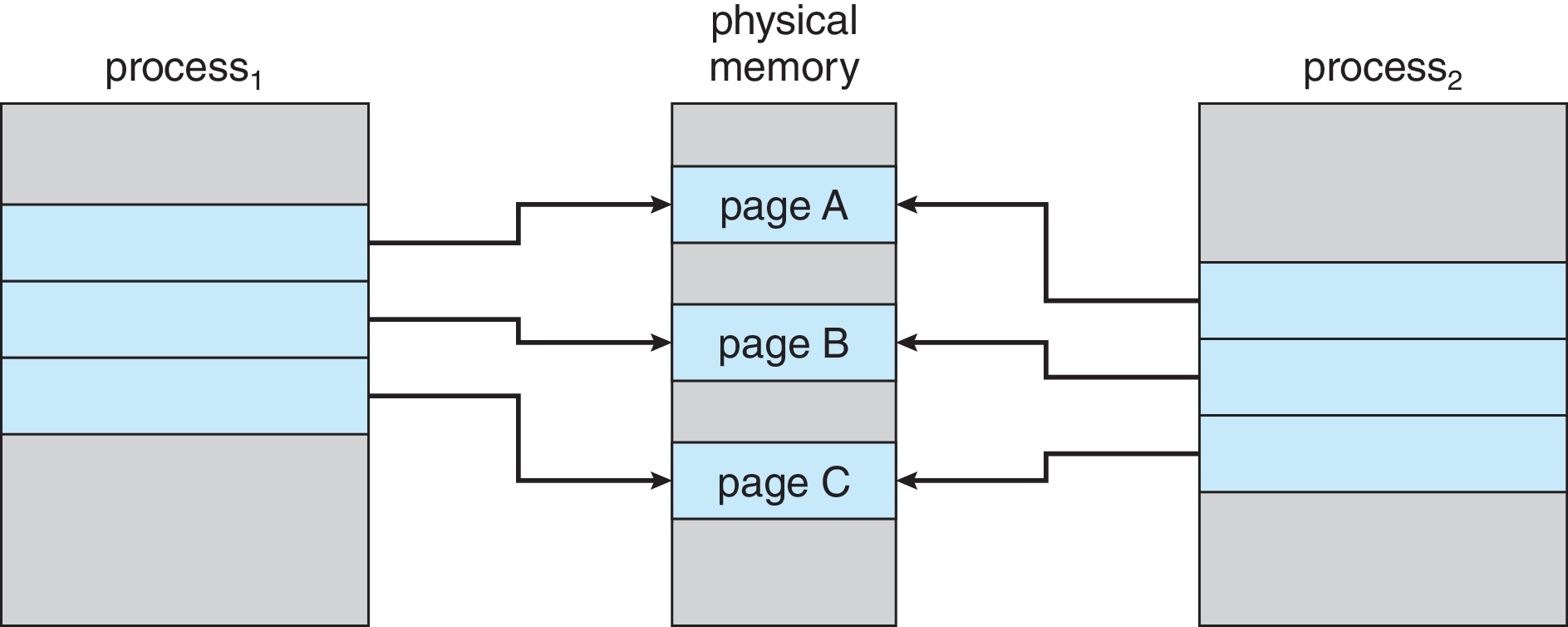
Figure 10.7: Before process 1 modifies page C 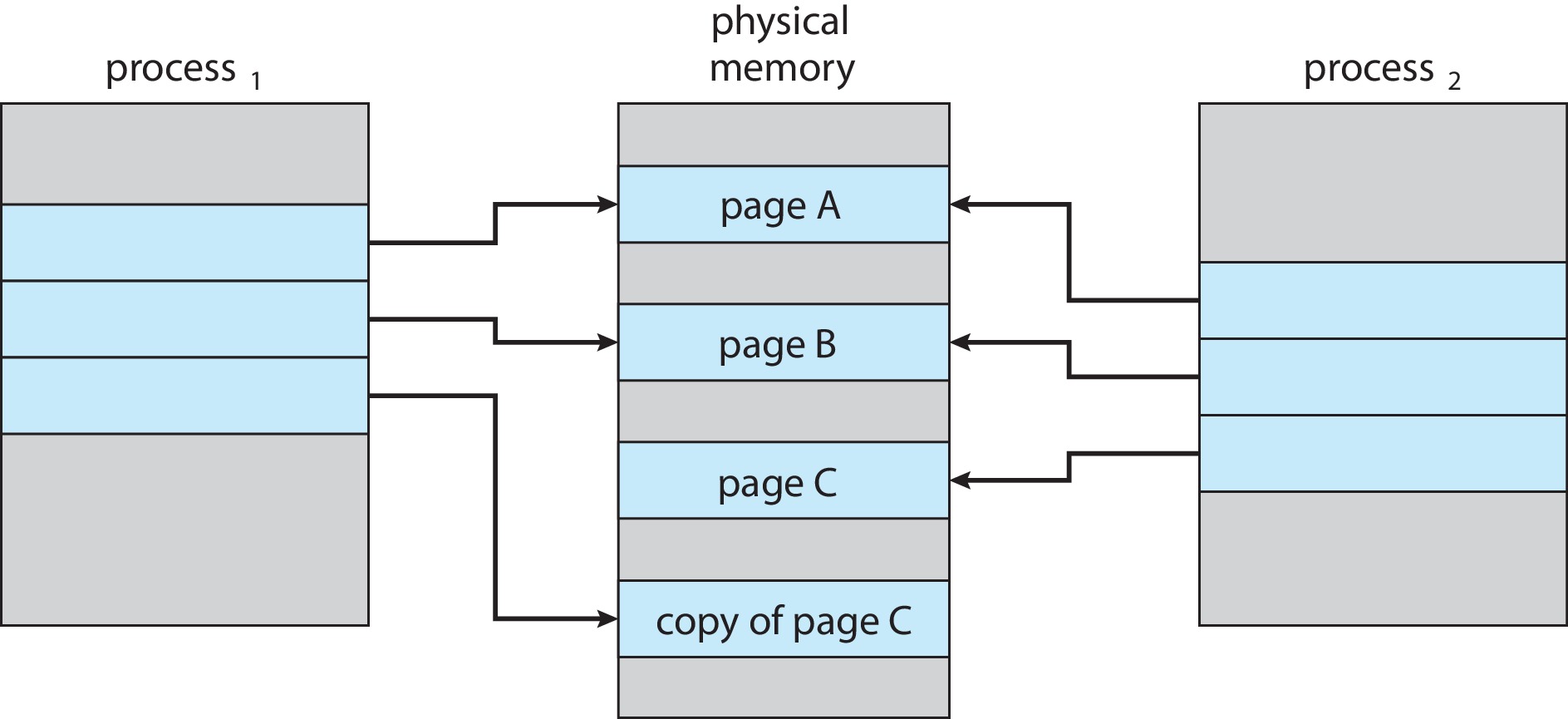
Figure 10.8: After process 1 modifies page C - Copy-on-write saves time if the child process does an exec() right after
it is created.
- If the child process does not exec(), copy-on-write assures that only as much
new memory as necessary will be allocated.
- Some versions of unix utilize another variant of fork() called vfork(). With vfork(), the parent sleeps while the child uses the address space of the parent. The child is not supposed to write to the parent's space. The child is expected to soon use a form of exec, which gives the child a new address space of its own, separate and distinct from that of the parent. When the parent wakes it will see any changes the child made to the parent's address space, so caution is critical. This is considered dangerous and inelegant but efficient.
- Physical memory may become over-allocated --
there may be no free frames when a page-fault occurs! The
standard solution is called page replacement.
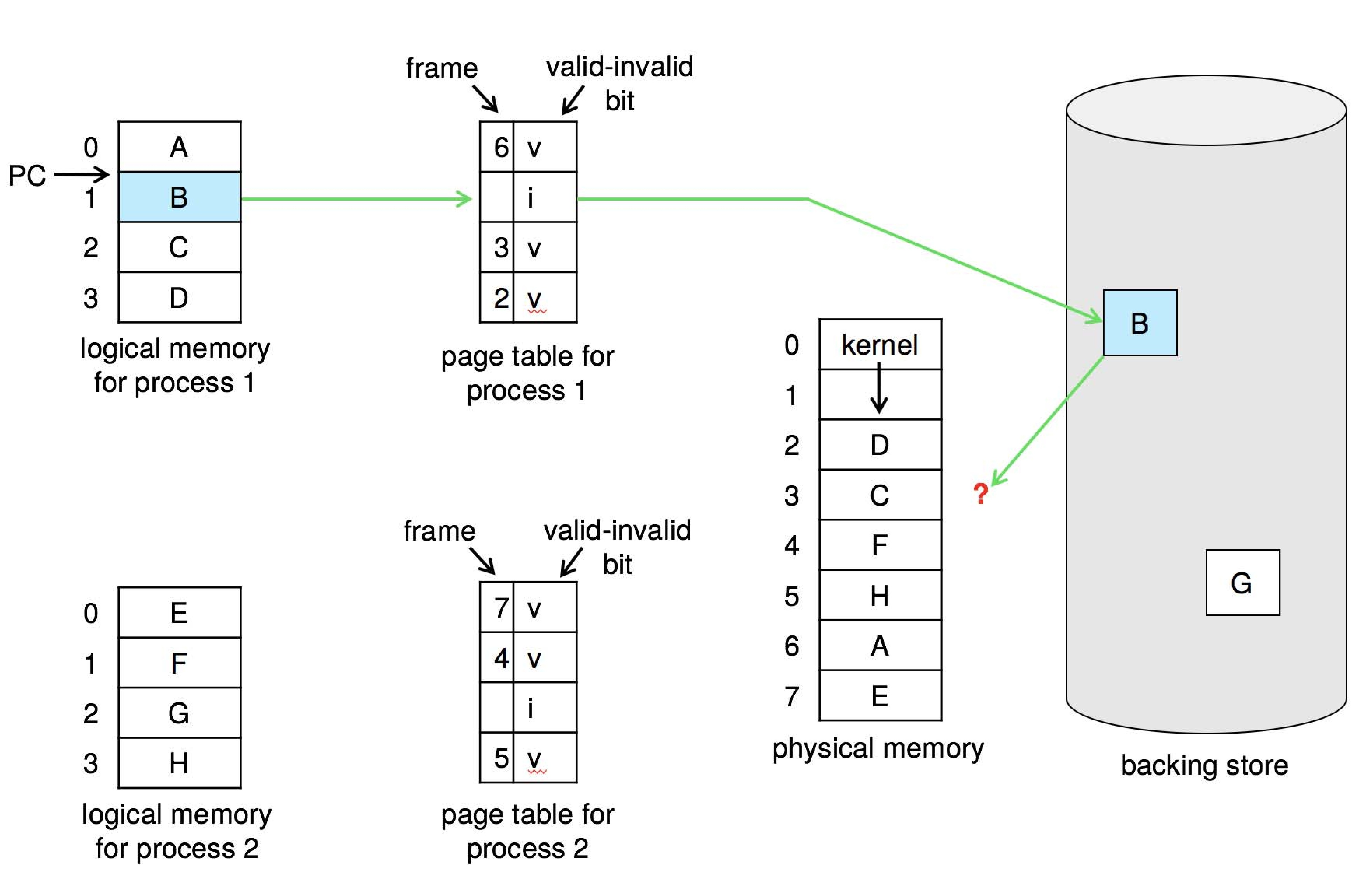
Figure 10.9: Need for page replacement -
10.4.1 Basic Page Replacement
- If there is no free frame to service a page-fault then
one way to handle the problem is to
use a frame that is NOT free,
but which does not appear to be needed
too badly
by the process that is currently using it.
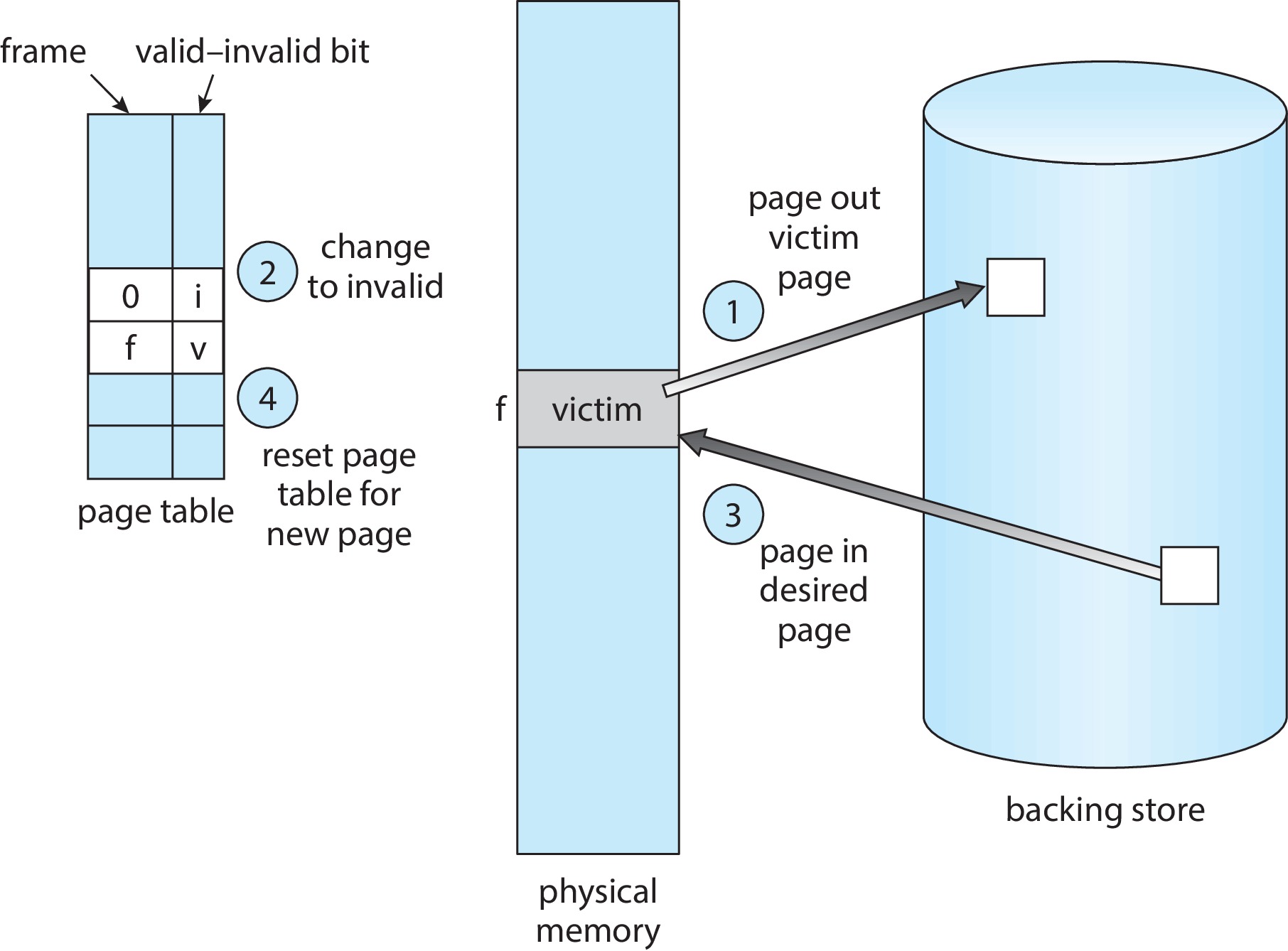
Figure 10.10: Page replacement -
The OS writes the contents of the "victim" frame to swap space first,
if it has been modified
(as recorded in the "modify bit" (a.k.a. "dirty bit")
associated with the frame). Otherwise, to save time,
the OS *does not* write the frame. (If for some reason
the page is missing from swap space and needs to be there,
then write it anyway.)
- When performing page replacement, the OS must update data
structures to reflect the change to the use of the frame.
For example, it has to make changes to the frame table, and
to the page tables of the processes that gain and lose the frame.
(It's possible for the process that gains to be the same as
the loser.)
- Each OS needs a solution to its
frame-allocation problem:
How many frames shall be allocated to each process?
- The OS also must have a page-replacement algorithm:
When a page is to be replaced, which frame shall
be the "victim"?
We want a replacement algorithm that is best for keeping
the page-fault rate low.
- We evaluate a page replacement algorithm by trying it out on
some reference strings.
- Suppose you make a list L of all the logical memory
addresses referenced by a process P during its lifetime, in
the order the references are made. Suppose you make a list
L' from L by just using the page numbers of each address
from L. Suppose you then "consolidate" L' into a third list
L" by "collapsing" all runs of the same page number into
just one "copy" of that page number. The result would be
the reference string of the process P.
The reference string of a process is a sequence of transitions that the process makes. Each item in the reference string represents the process beginning to access a page that it was not accessing immediately beforehand. A page fault can happen only when a process makes such a transition.
- The length of a reference string is just the number
of items in the sequence.
- We can evaluate a page-replacement algorithm by counting page faults on reference strings. We count the number of page faults a process gets when it uses an algorithm on a reference string.
- If there is no free frame to service a page-fault then
one way to handle the problem is to
use a frame that is NOT free,
but which does not appear to be needed
too badly
by the process that is currently using it.
-
10.4.2 FIFO Page Replacement
- The operating system can link records
representing all the occupied frames into a FIFO queue. When a
page is loaded into a frame the corresponding record goes into
the back of the queue. When a victim for page replacement is
needed the frame at the front of the queue is selected. This
is called FIFO page replacement.
-
FIFO page replacement is easy to understand and implement but
tends not to do very well at keeping the page-fault rate
low.
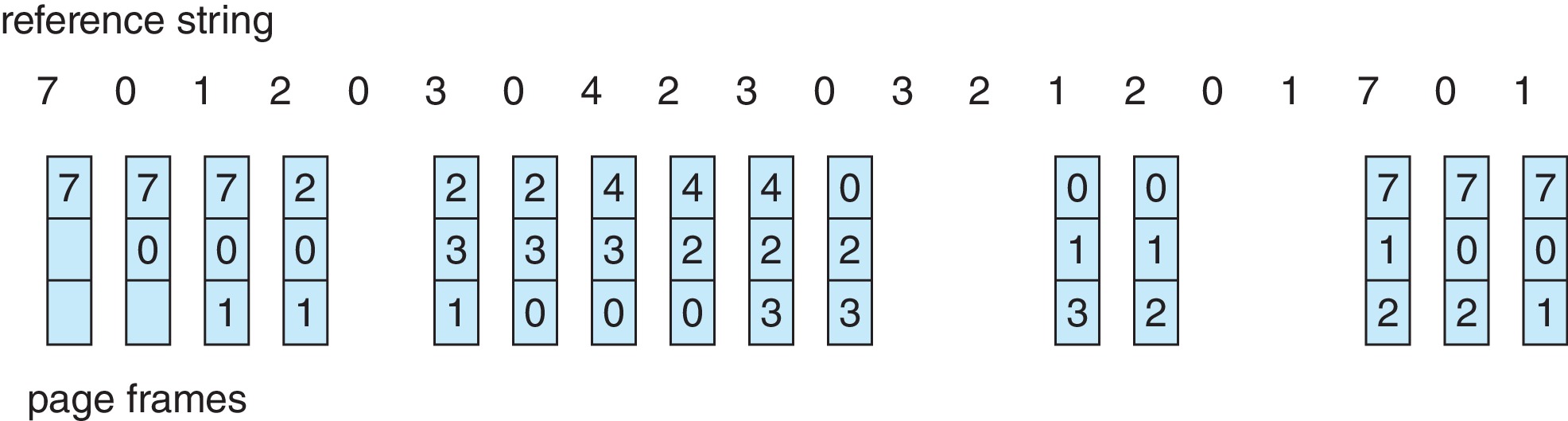
Figure 10.12: FIFO page replacement algorithm - FIFO replacement requires updates to data structures only when
a frame is loaded or a victim frame is selected.
- FIFO page replacement is subject to Belady's anomaly: the page
fault rate for the same reference string can sometimes go up
when you increase the number of frames available!
(The phenomenon is named after its discoverer, computer scientist
László Bélády.)
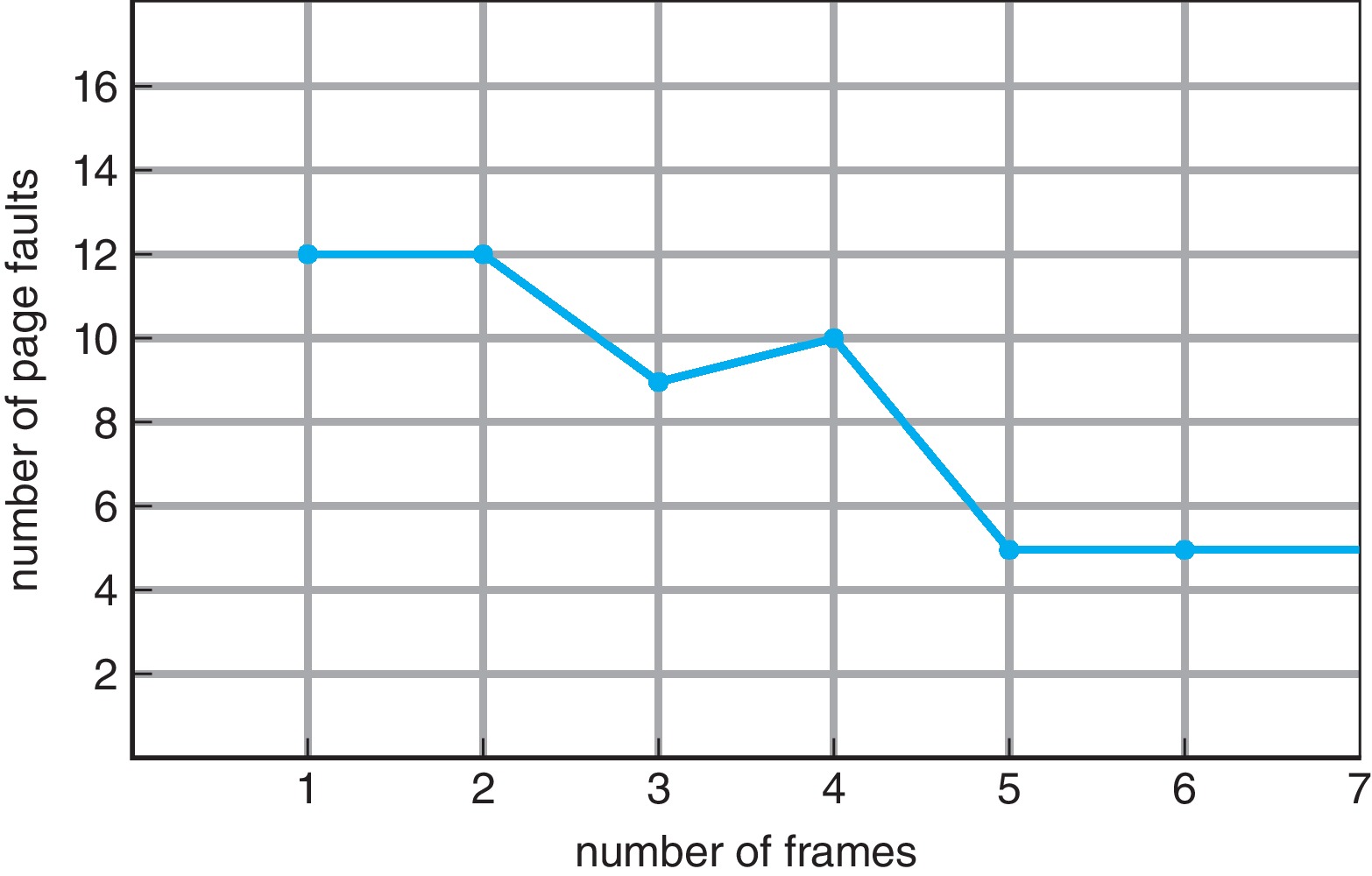
Figure 10.13: Page fault curve for FIFO replacement on a reference string
- The operating system can link records
representing all the occupied frames into a FIFO queue. When a
page is loaded into a frame the corresponding record goes into
the back of the queue. When a victim for page replacement is
needed the frame at the front of the queue is selected. This
is called FIFO page replacement.
-
10.4.3 Optimal Page Replacement
- Interestingly,
there is a page replacement policy that is
known to be "as good as possible."
- It gives the lowest possible page-fault rate, guaranteed.
- In essence, the algorithm is to
"replace the page that will not
be used for the longest period of time."
- We can think of it as the LNU algorithm:
"replace the page with the
latest next use."
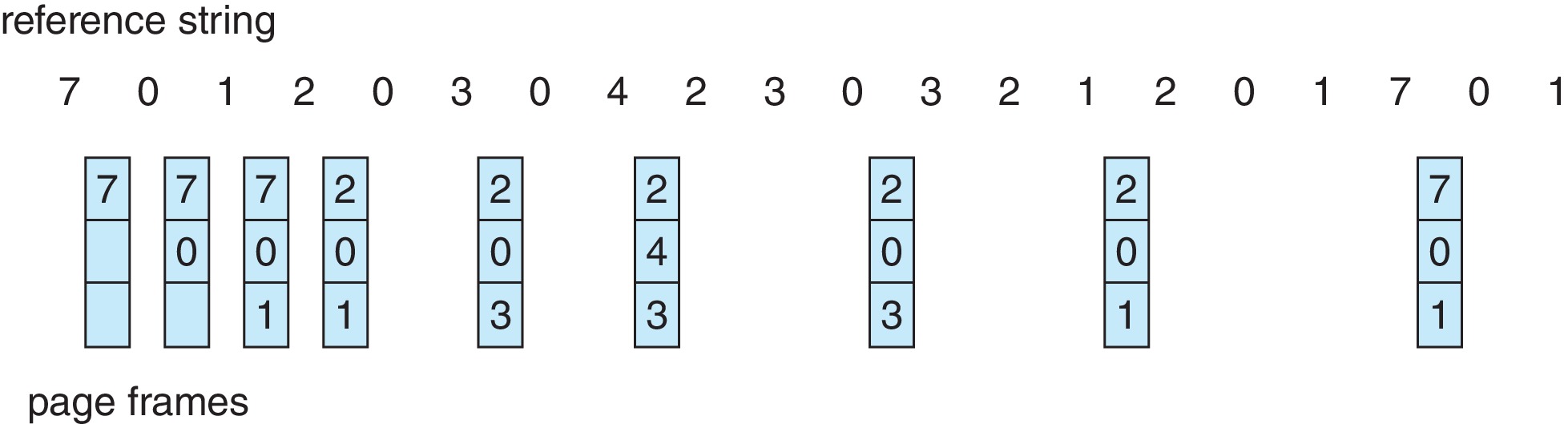
Figure 10.14: Optimal page-replacement algorithm - This algorithm is also called "OPT" or "MIN."
- Sometimes it is called the oracle method
because it requires the OS to know the future reference string
of the process.
- Usually, the future reference string can not be known, so
it is seldom possible to implement the OPT algorithm.
(The reference string of a process generally
depends on the outcomes of branch instructions, which in
turn generally depend on what data is input to the process.)
- However we can evaluate other page-replacement algorithms by comparing their performance with that of OPT on pre-selected reference strings.
- Interestingly,
there is a page replacement policy that is
known to be "as good as possible."
-
10.4.4 LRU Page Replacement
- The idea of LRU is to
replace the page that is "least recently
used" -- i.e. the page that has not been accessed for the
longest time.
- Because LRU is similar to OPT -- it just looks "back" instead
of "ahead" -- it seems plausible that LRU may tend to have low
page fault rates. (LRU might be called EPU for "Earliest Previous
Use." This underscores the fact that
LRU is the "mirror image"
of the OPT algorithm: "Latest Next Use.")
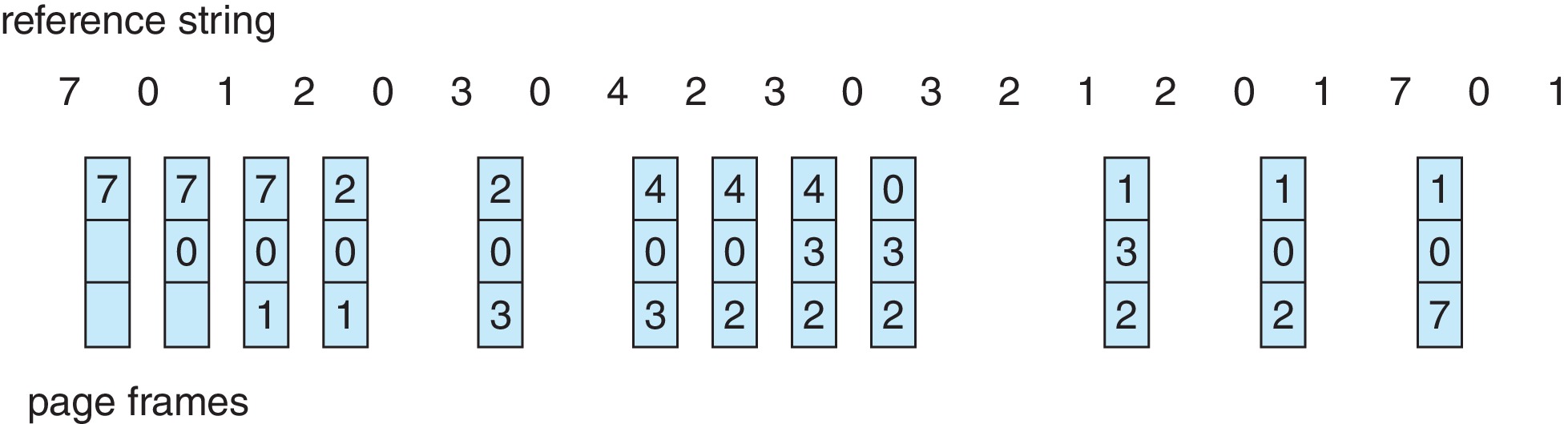
Figure 10.15: LRU page-replacement algorithm -
LRU works well generally, but it can fail miserably in some
situations. It doesn't work very well in the example above, but it works
better than FIFO replacement.
- LRU replacement requires very frequent updates to data
structures -- each time there is a memory reference.
- In theory we could implement LRU by arranging for
hardware to perform a kind of time-stamping.
Hardware would increment a counter after every
memory reference, and write the value of the counter into the
page table entry (PTE) every time a page is accessed. The OS
would search page tables for the lowest value of the counter
to find the LRU page for replacement.
- Another method would be for the hardware to perform updates to
an array of records indexed by page number or frame number.
The records would contain pointer fields which would be used to
implement a 'stack' as a doubly-linked list.
Each time a
reference is made to a page the hardware would
have to index into the array and place the referenced frame at
the top of the stack by manipulating pointers (no more than
six). The LRU frame for replacement would just be the frame on
the bottom of the stack.
- OPT and LRU are stack algorithms -- the set of pages
in memory for an allocation of N frames is a subset of the
set of pages in memory for an allocation of N+1 frames.
- To see that LRU is a stack algorithm, note that when doing
LRU with N frames, the pages in memory are the N most
recently referenced pages.
- Stack algorithms do not suffer from Belady's anomaly.
- The idea of LRU is to
replace the page that is "least recently
used" -- i.e. the page that has not been accessed for the
longest time.
-
10.4.5 LRU-Approximation Page Replacement
- Most computers do not have hardware support for true LRU
page-replacement
-
Many systems do have a reference bit associated with
each page table entry.
-
When a reference is made to an address in a page the
hardware sets the corresponding reference bit
to indicate that the page has been accessed.
-
The operating system is able to clear reference bits.
- We can implement page replacement algorithms that are
approximations of pure LRU by using manipulation of reference
bits.
-
10.4.5.1 Additional-Reference-Bits Algorithm
- In this scheme the OS keeps a table containing
(say)
one byte of memory associated with each page.
Periodically an interrupt gives the OS control and
the OS rolls the value of each reference bit into
the most significant bit (msb) of its corresponding byte.
After rolling a reference bit, the OS clears it to
prepare for the next cycle. Examples:
- If the byte is 0000 0000 then the page has not been
referenced for eight periods in a row.
- If the byte is 1111 1111 then the page has been
referenced in all of the last eight periods.
- If the byte is 0100 1000 then the page was referenced
two periods ago, and also five periods ago.
- If the byte is 1000 0100 then the page was referenced
in the latest period and also six periods previously.
- If the byte is 0000 0000 then the page has not been
referenced for eight periods in a row.
- Note that if we just view these bytes as unsigned integers
then the smaller values correspond to the pages that are
less recently used.
- When the OS needs to choose a victim for page-replacement it picks a page with minimal byte-value. This algorithm approximates LRU.
- In this scheme the OS keeps a table containing
(say)
one byte of memory associated with each page.
Periodically an interrupt gives the OS control and
the OS rolls the value of each reference bit into
the most significant bit (msb) of its corresponding byte.
After rolling a reference bit, the OS clears it to
prepare for the next cycle. Examples:
-
10.4.5.2 Second-Chance Algorithm
- In the typical implementation of the 2nd-chance algorithm
there is a circular linked list of records. Each record
represents one physical frame.
- An external
pointer points to the current element of the list.
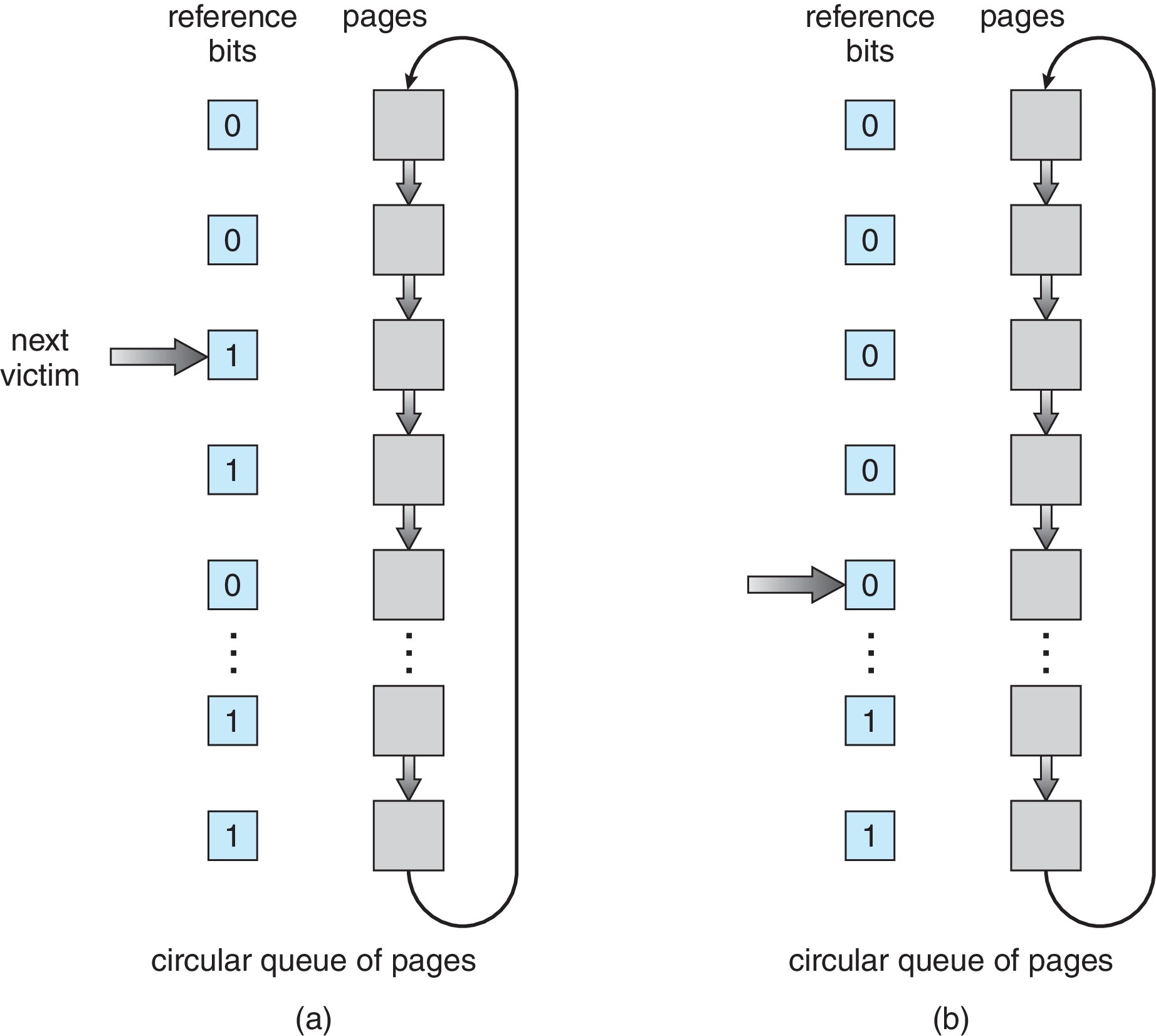
Figure 10.17: Second-chance (clock) page-replacement algorithm -
When the OS needs a victim
frame it executes the
following algorithm:
- examine the current element.
-
If the reference bit of the frame is 0 (the frame
has not been referenced lately) then make the frame
the victim. Copy the new page into the frame
and advance the pointer to the next frame.
- Otherwise (the reference bit of the frame is 1 because it was accessed recently) do not make the frame a victim (give it a second chance). Clear the reference bit. Advance the pointer to the next frame. Go to step 1.
- examine the current element.
- In the typical implementation of the 2nd-chance algorithm
there is a circular linked list of records. Each record
represents one physical frame.
-
10.4.5.3 Enhanced Second-Chance Algorithm
- The enhanced version is like straight 2nd chance except
we keep looking until we find a victim for which both
the reference bit and and the modify bit are 0.
(or until we come back around to
where we started.)
- If we do come back around without getting a victim, then we go
around again until finding any unreferenced frame.
- If there is other process activity going on concurrently
with this, the OS may have to go around again and choose a
referenced clean frame, or even go around a fourth time
and choose a referenced dirty frame.
- It is said that the method above was used in a version of the Macintosh OS. I don't know if it is currently in use with OS X.
- The enhanced version is like straight 2nd chance except
we keep looking until we find a victim for which both
the reference bit and and the modify bit are 0.
(or until we come back around to
where we started.)
- Most computers do not have hardware support for true LRU
page-replacement
-
10.4.6 Counting-Based Page Replacement
- If we can arrange for a counter (or an approximation) to track how many references have been made to each frame then we can implement a least-frequently-used or most-frequently-used page-replacement algorithms. These algorithms don't generally tend to have very good performance, and the overhead of the implementation is high.
-
10.4.7 Page Buffering Algorithms
-
As an optimization the system may keep a pool of clean free
frames
-- when a dirty victim is selected the new page is
immediately copied into a clean free frame from the pool and
can be used right away. The dirty victim is then written back
to swap space. After that, the now clean victim becomes part of
the pool. (Note that it will still contain its original content,
unless something special, like zero-filling, is done.)
- Another optimization is for the OS to keep the pool of free
frames, and also to remember the page for which each frame was
previously used. If a process faults on a page whose old frame
happens to still be in the pool, then the OS just gives that same
frame back to the process. That way the OS avoids the work of reloading
the page from disk. (This is sometimes called
"reclaim from free.")
- The OS can also keep track of which (allocated) pages are dirty and "in its spare time" write dirty pages to swap space. This way, when a page has to be replaced it is more likely to be clean, and hence more likely to be replaced quickly. If the OS is maintaining a pool of free frames, this idea of writing back allocated frames is still worthwhile because it tends to help keep excessive requests from draining the pool.
-
As an optimization the system may keep a pool of clean free
frames
-- when a dirty victim is selected the new page is
immediately copied into a clean free frame from the pool and
can be used right away. The dirty victim is then written back
to swap space. After that, the now clean victim becomes part of
the pool. (Note that it will still contain its original content,
unless something special, like zero-filling, is done.)
-
10.4.8 Applications and Page Replacement
- This section points out that some applications, because they have special characteristics and needs, should manage their own primary and secondary memory to the greatest extent possible, and NOT rely on operating system page-replacement algorithms or other file-system services. By using "raw I/O," some applications can function much more efficiently. Databases and data warehouses are examples of such applications.
- How many frames should be made available to a process? Should it be
allowed to take frames away from other processes?
- Should frames for user pages and frames for file buffers and heap
storage all go into the same pool, or should there be separate free
lists for the different usages?
- Should the system allow free lists or pools of free memory to drain
completely, or should some minimum size be maintained at all costs?
-
10.5.1 Minimum Number of Frames
- A process cannot execute an instruction unless the instruction
and all the data that the instruction accesses are entirely
resident in physical memory.
- If an instruction straddles two pages and the data it acts on
straddles two or more pages then it may be necessary to have
four or more pages resident in memory in order for that
instruction to execute.
-
For every computer architecture there is some worst case
scenario. There is some largest number N such that a process
may need N resident pages in order to execute
a single instruction.
- That being the case, the operating system must be set up to allow any process to have at least N frames. In the worst case, the process would not be able to execute if it could not get N frames allocated to it simultaneously.
- A process cannot execute an instruction unless the instruction
and all the data that the instruction accesses are entirely
resident in physical memory.
-
10.5.2 Allocation Algorithms
- It's possible to give nearly equal numbers of free frames to
all processes. That is called equal allocation.
-
Probably it makes more sense to use proportional allocation,
to allocate free frames to processes in proportion
to their "need." Need may be measured in various ways.
Larger processes or higher-priority processes may be judged
to be more needy.
- It's possible to give nearly equal numbers of free frames to
all processes. That is called equal allocation.
-
10.5.3 Global Versus Local Allocation
-
When it replaces a page, the OS selects a frame used by process
X, and loads it with a page needed by process Y.
-
Under a global page-replacement policy, X and Y
don't have to be the same process.
- Under a local page-replacement policy X and Y do
have to be the same process.
-
Global replacement policies are more common,
perhaps because
they allow the number of frames allocated to a process to
change according to changing need.
-
With global replacement, ideally there is a "Robin Hood"
effect:
the operating system steals frames from "rich"
processes (that don't need them) and gives them to "poor"
processes (that do need them).
- If everything works out perfectly then each process has the
frames it needs to maintain a low page-fault rate. This
should result in high average throughput.
- On the other hand, there are other ways to dynamically alter
the number of frames allocated to each process. If we use
such an allocation strategy in conjunction with a local
page-replacement policy, might we allow processes finer
control over their own page-fault rates?
- An OS typically utilizes minimum and maximum thresholds
to trigger one or more page-replacement processes, often
called reapers. When the number of free frames drops
below the minimum threshold, the reaper replenishes the supply
of free frames by taking frames away from user processes. The
reaper sleeps when the supply is above the maximum threshold.
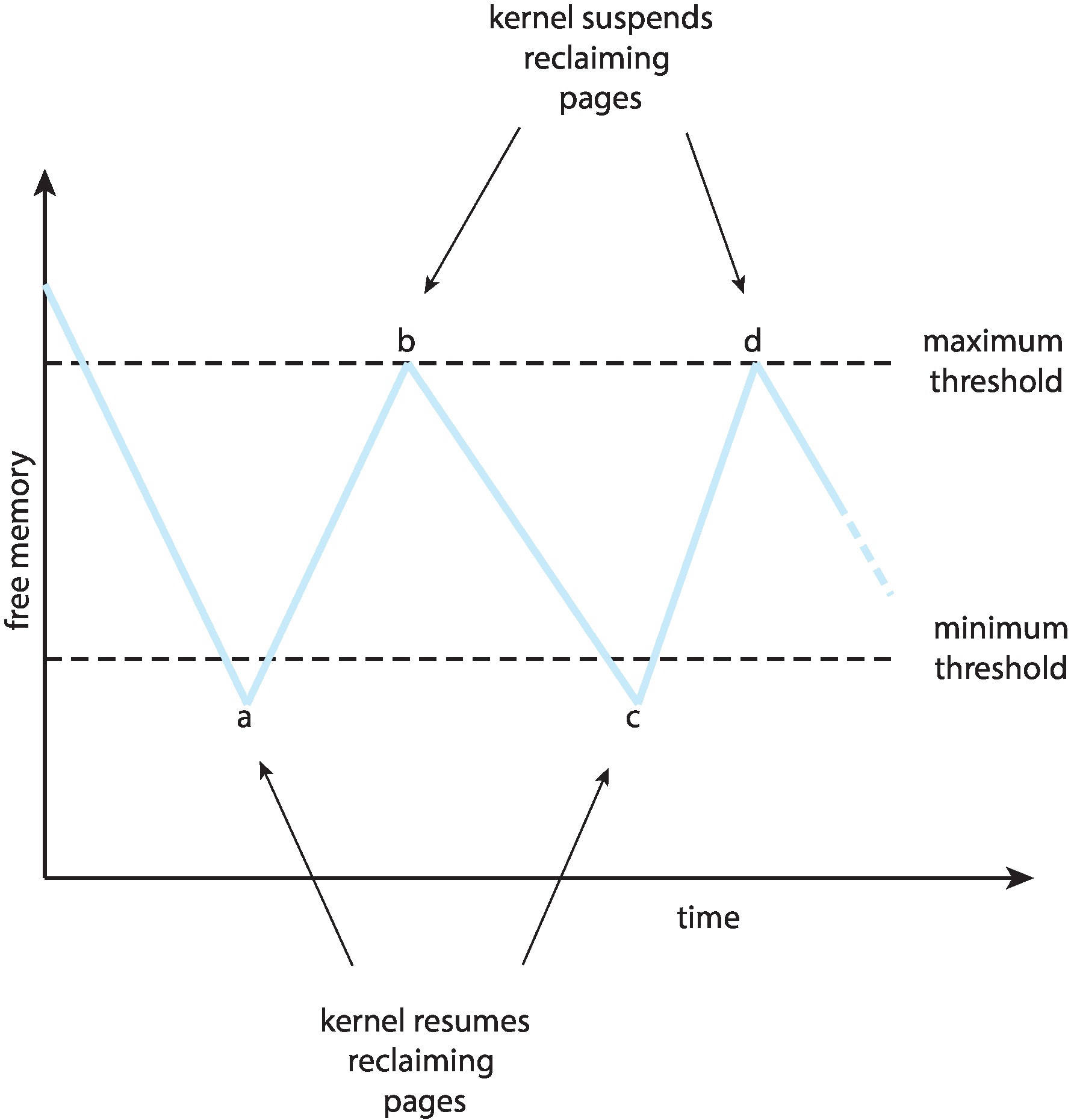
Figure 10.18: Reclaiming pages - If a shortage of frames becomes extreme, the OS may reap frames more and more aggressively. It may resort to swapping out whole processes, or even terminating processes. Linux has a an out-of-memory killer process.
-
When it replaces a page, the OS selects a frame used by process
X, and loads it with a page needed by process Y.
-
10.5.4 Non-Uniform Memory Access
- Many multiprocessor systems have multiple system boards,
each with multiple CPUs and some primary memory. This
usually means that a CPU can access the memory on its own
system board more quickly than the memory on other boards.
This is non-uniform memory access (NUMA).
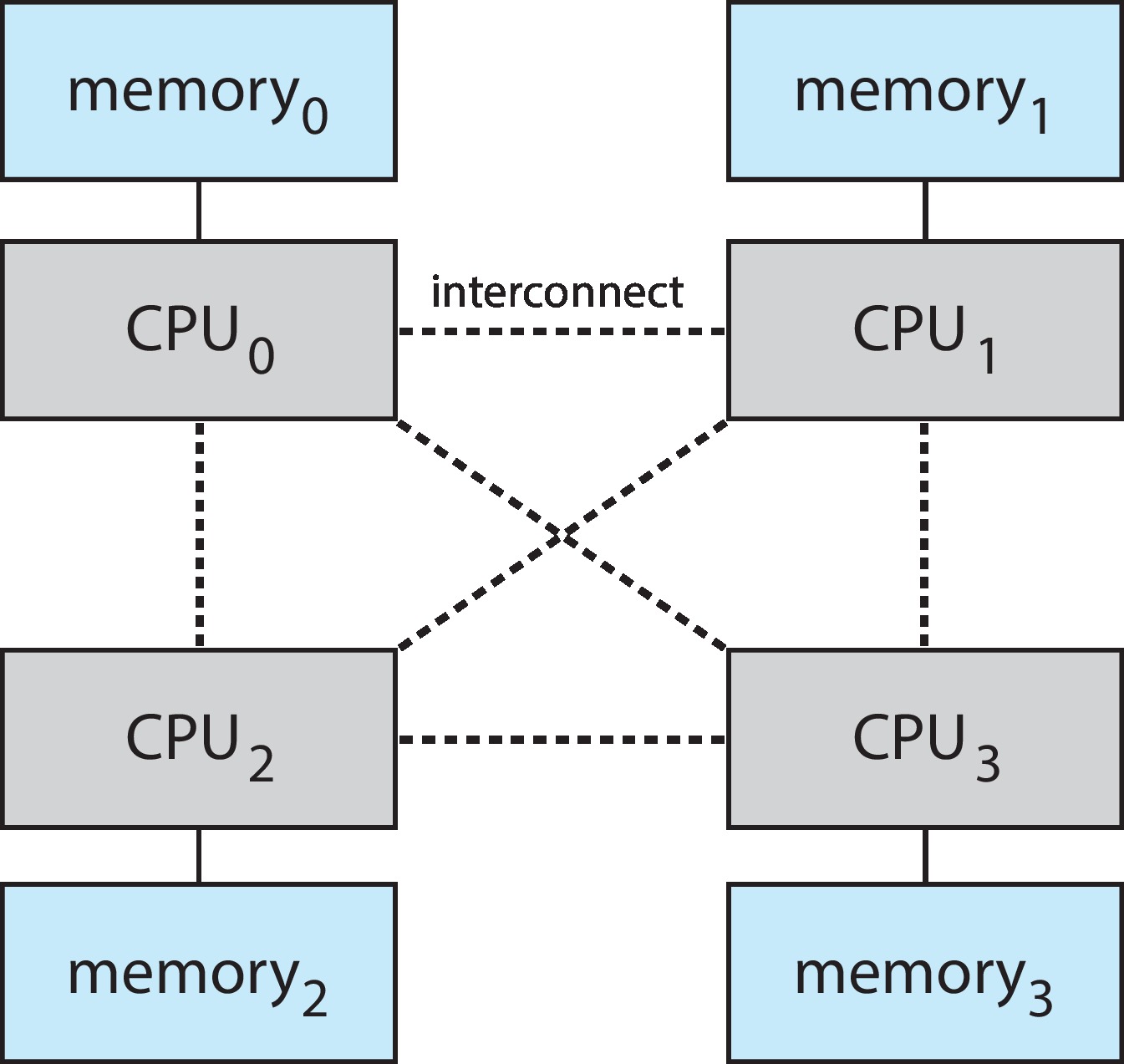
Figure 10.19: NUMA multiprocessing architecture - An individual thread tends to run slower on a NUMA system than on
a system with uniform memory access. However NUMA systems
support greater numbers of CPUs, and thus they can have higher
levels of parallelism and throughput.
- On NUMA systems, it is desirable for the OS to allocate all primary
memory for a process on one particular system board, and to
insure that the process executes on a CPU on that same board.
The result is likely to be high cache hit rates and short memory
access times.
- If the process is multithreaded, this manner of scheduling is more challenging. Linux and Solaris are examples of operating systems that have approaches to solving the problem. They have hierarchies of CPUs and memory (Linux "scheduling domains" and Solaris "lgroups"). These are groups of CPUs and memory areas that are mutually close, meaning that the latency between each pair of elements is low. For a multi-threaded process, the OS tries to assure that all the threads use CPUs and memory in just one of the groups, or all in mutually "nearby" groups.
- Many multiprocessor systems have multiple system boards,
each with multiple CPUs and some primary memory. This
usually means that a CPU can access the memory on its own
system board more quickly than the memory on other boards.
This is non-uniform memory access (NUMA).
If a process has a severe shortage of frames, it may get so many page faults that the time spent servicing its page faults exceeds the time it spends executing. That is the phenomenon of thrashing.
-
10.6.1 Cause of Thrashing
- Suppose the degree of multiprogramming is very low. Say,
to use an extreme example, there are only two or three active
user processes. In that case it will be likely that all those
processes will be waiting for I/O at the same time quite often.
At those times the CPU will be idle. CPU utilization is low
in such a system. Assuming there is adequate memory available,
it will probably help utilization if we increase the degree
of multiprogramming.
- On the other hand if the degree of multiprogramming is very
high, and if physical memory is over-allocated then it is likely
that there will be a lot of thrashing going on. In that case
too, the CPU utilization may be quite low because often all
processes will be blocked waiting for paging and other I/O
operations to complete. In this case it will only make things
worse to increase the degree of multiprogramming.
- According to the principle of locality the
typical process usually spends relatively long periods
of time accessing a relatively small locality.
A locality is a subset of its text and data that
the process has been accessing recently.
Relative to memory access time, the locality of
the processes tends to change very slowly.
According to this view
the process will not thrash as long as it has enough frames
to hold all or most of its current locality.
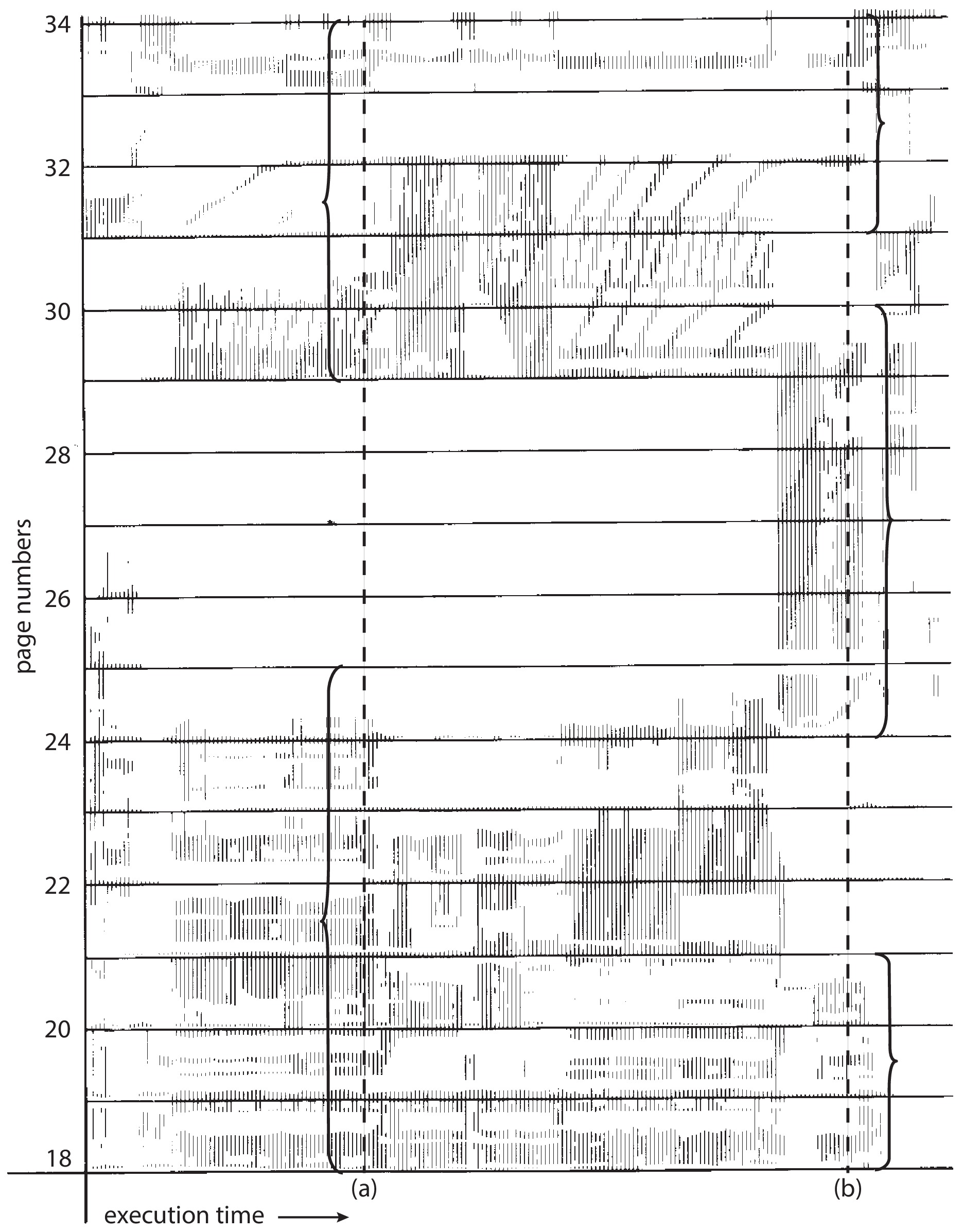
Figure 10.21: Locality in a memory-reference pattern - As an example of a process remaining in one locality for a long time, consider how a process acts while it executes a loop. The only instructions the process accesses are the instructions of the loop body and the instructions of the loop control. Quite possibly the process will only access a small portion of its data while executing the loop. It is a very common thing for a process to spend a long time executing in a loop.
- Suppose the degree of multiprogramming is very low. Say,
to use an extreme example, there are only two or three active
user processes. In that case it will be likely that all those
processes will be waiting for I/O at the same time quite often.
At those times the CPU will be idle. CPU utilization is low
in such a system. Assuming there is adequate memory available,
it will probably help utilization if we increase the degree
of multiprogramming.
-
10.6.2 Working-Set Model
- We can pick a number Δ (delta) and arrange for the system
to count or approximate the number of (distinct) pages
referenced during the last Δ memory references. For
example, we may set Δ = 10,000 and estimate the number of
pages accessed in the last 10,000 memory references. (This will
require some combination of actions performed by hardware and
the OS -- e.g. keeping a history of the values of reference bits.)
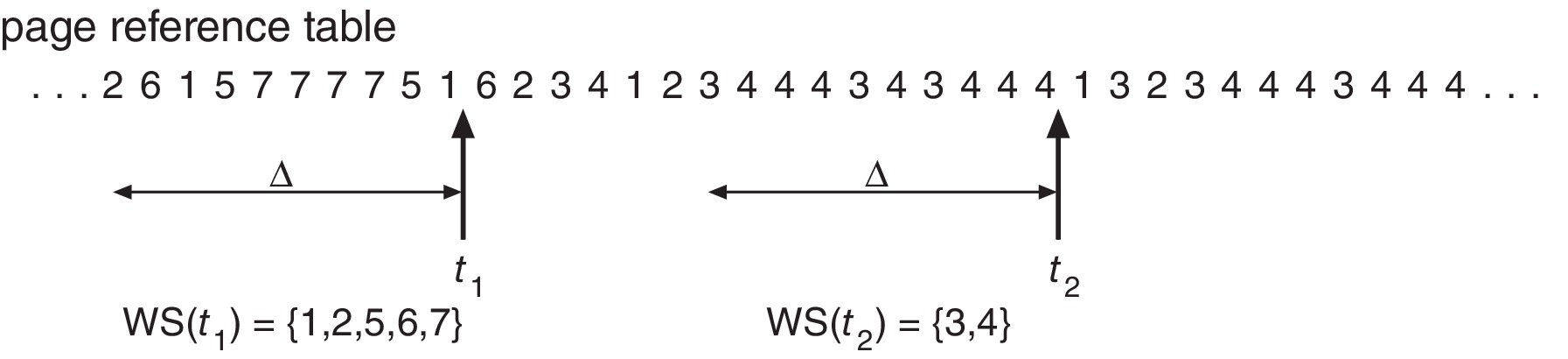
Figure 10.22: Working-set model -
The set of pages referenced during the last Δ references
is called the working set. It is an approximation of the locality
of the process. The goal of the OS would be to use this approximation
to help keep each process supplied with enough frames
to hold its working set.
- If the OS uses this approach, and if there are sufficient jobs available,
it seems reasonable that the OS will be able to keep the degree of
multiprogramming high enough to attain good CPU utilization and low
enough to prevent thrashing.
-
When all processes have enough frames for the current size of their
working sets, and when there is enough additional memory, the OS
would be able to place another job into memory.
- When memory is in short supply and processes can't get enough for their working sets, the OS might have to terminate processes or swap them out, and divide their allocations among the remaining processes that need more frames.
- We can pick a number Δ (delta) and arrange for the system
to count or approximate the number of (distinct) pages
referenced during the last Δ memory references. For
example, we may set Δ = 10,000 and estimate the number of
pages accessed in the last 10,000 memory references. (This will
require some combination of actions performed by hardware and
the OS -- e.g. keeping a history of the values of reference bits.)
-
10.6.3 Page-Fault Frequency
- Instead of the working set, to control thrashing,
it is more direct and simple to work with the page-fault frequency (PFF)
of a process.
- Establish upper and lower bounds for page-fault frequencies.
-
If the PFF of a process exceeds the upper bound, give the process
more frames until the PFF goes below the upper bound.
- If the PFF of a process falls below the lower bound, then take
frames away from the process until the PFF is above the lower bound.
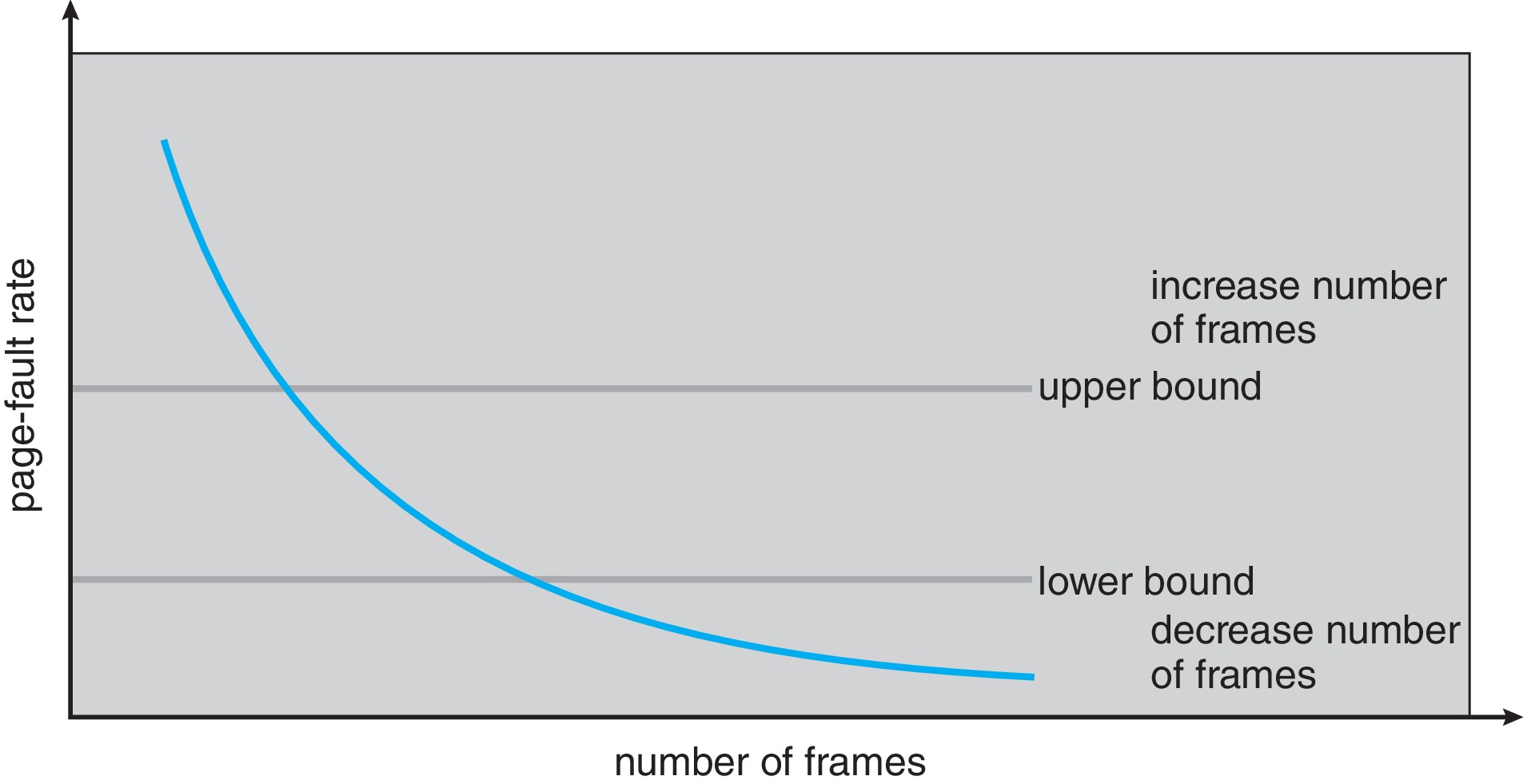
Figure 10.23: Page-fault frequency - When there is a need to give frames to processes and there are
not enough frames, swap a process out and free its frames.
- When all processes have acceptable PFFs and there is memory to
spare, increase the level of multiprogramming.
- One possible drawback to the PFF approach is that it is not
sensitive to the difference between a change in size and a
transition of the working set. If the working set is not
changing in size, but merely transitioning from one locality to
another, it may be better for performance not to give more frames
to the process, but just to let page faults replace the pages that
are being "vacated" in favor of pages new to the working set.
- Also, it would be good if the system keeps track of the working set of each process, to help with pre-paging.
- Instead of the working set, to control thrashing,
it is more direct and simple to work with the page-fault frequency (PFF)
of a process.
-
10.6.4 Current Practice
- Virtual memory has a lot of advantages. It's helpful and useful. However, its ability to compensate for a lack of physical memory is quite limited. In order to get good performance, it remains very important to provision systems with generous amounts of physical memory.
- When performing page replacement, it may be necessary to replace modified frames.
The common way to handle such frames has been for the OS to copy them out
to secondary storage before replacing them with their new contents.
Unfortunately, the copy-out operation is time-consuming.
- Memory compression is an alternative to copying out. The OS selects a set
S of several frames for replacement, and then compresses all their contents to
a size small enough to fit into a single frame. The OS takes a frame X from the
free list and puts the compressed data from S into X. Then the OS puts all the items
in S on the free list. The diagrams below indicate a before/after example.
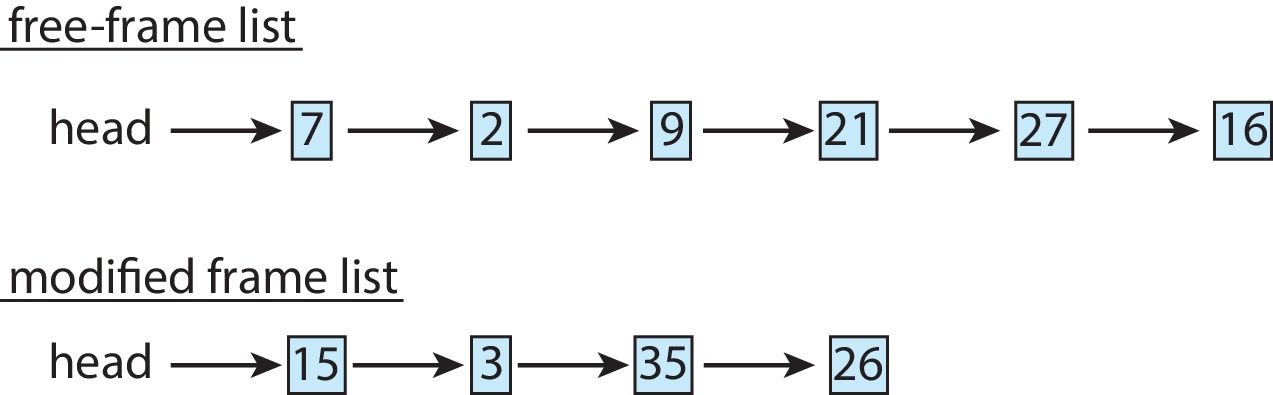
Figure 10.24: Free-frame list before compression 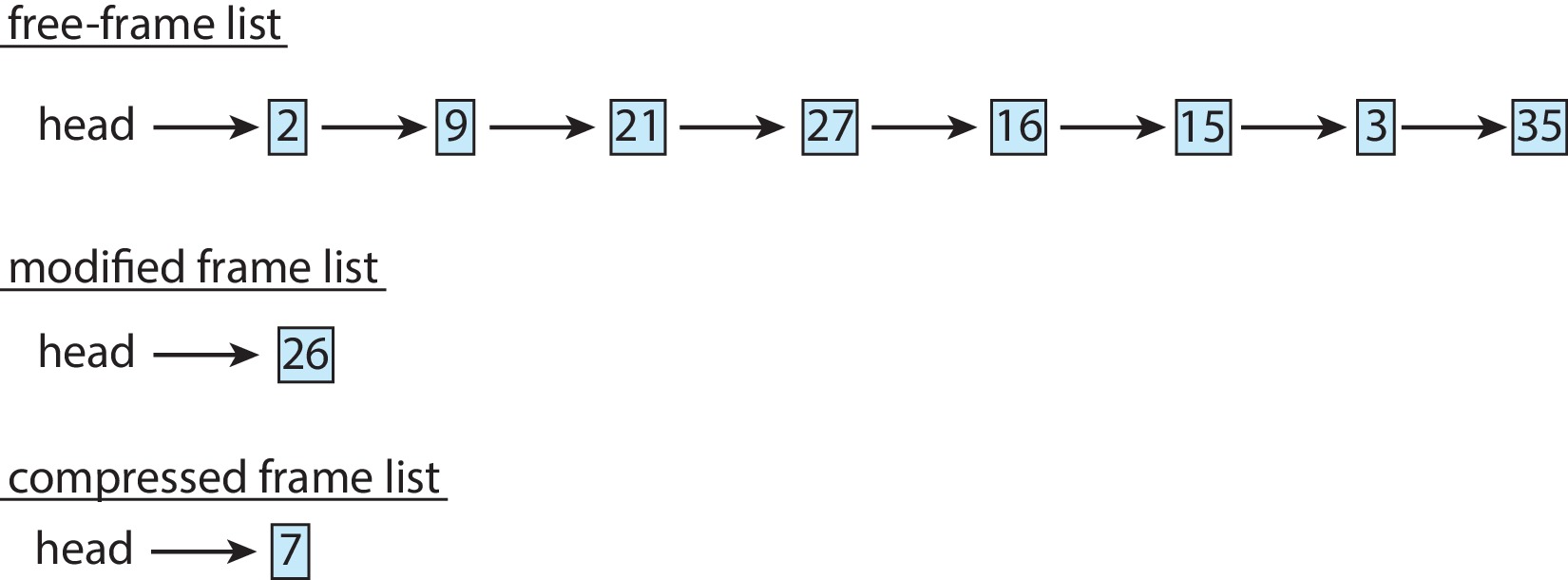
Figure 10.25: Free-frame list after compression - The OS maintains a separate list for frames that contain the compressed contents
of other frames.
- If a process faults on one of the frames that was compressed, the OS services the
page fault by decompressing the compressed frame, putting the decompressed info
back into free frames, and giving the process the frame on which it faulted.
- It is difficult for mobile operating systems to support swapping and paging.
Most of them use memory compression.
- Tests have shown that memory compression is faster than paging for desktop and
laptop computers. MacOS has been utilizing memory compression, since Version 10.9.
MacOS still resorts to paging when the results from memory compression are not
adequate.
- There is a trade-off between high compression and the speed of the compression algorithm. The algorithms in current use are considered fast, and they reduce pages to about 30 to 50 percent of their original sizes.
- An OS kernel typically has special memory allocation needs.
- The OS may require kernel code and data to be entirely
resident in physical memory at all times, even though
virtual memory is implemented for user processes.
- The OS may need large numbers of data structures that have sizes
that are not compatible with the page size. The size, D, of a structure
may be smaller than a page, but the page size may not be a multiple of D.
On the other hand, D may be larger than a page but D may not be a
multiple of the page size. If memory for such structures is allocated
using standard frames, there can be an unacceptable amount
of internal fragmentation.
- Some hardware devices may be configured so that they have to interact with a set of contiguous frames of physical memory.
To facilitate conservation of memory, usually there are special memory-allocation techniques and methods available to the kernel.
- The OS may require kernel code and data to be entirely
resident in physical memory at all times, even though
virtual memory is implemented for user processes.
-
10.8.1 Buddy System
- This model facilitates allocation of memory in contiguous
chunks of size equal to any power of two, up to some limit.
- The diagram shows how a 32 KB chunk can be created for a
request for 21KB, by successively dividing portions of a
256 KB segment in half. The number of bytes in an allocation is
always the smallest power of 2 not less than the requested amount.
- Using the buddy system it's easy to coalesce some adjacent
deallocated chunks of equal size into single free chunks.
The coalescence can 'cascade' easily, leading to the reformation
of larger and larger chunks, which then become available
for reallocation.
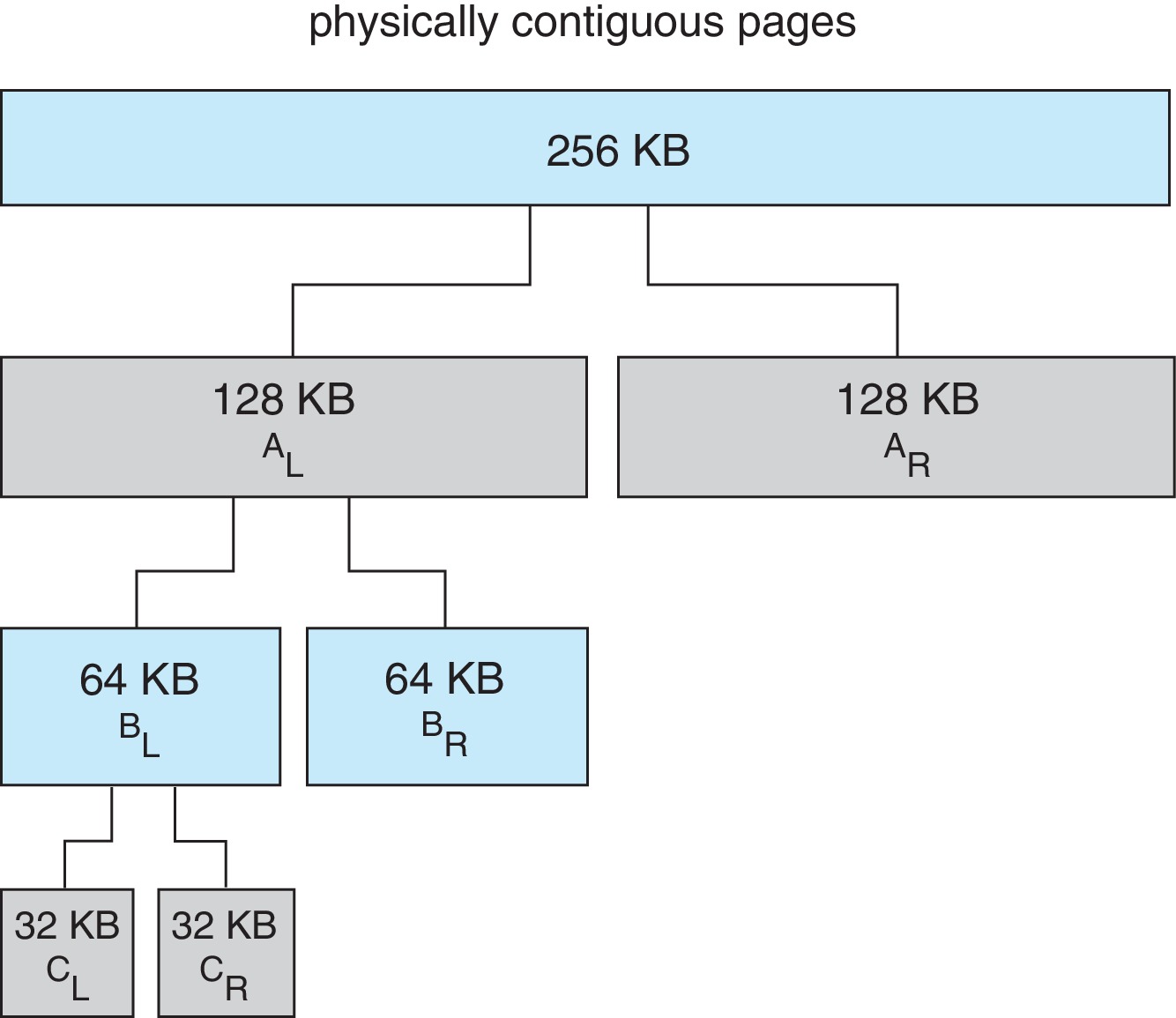
Figure 10.26: Buddy system allocation - Problem with the buddy system: An internal fragment can be nearly equal to the requested amount of memory. Therefore we cannot guarantee that total internal fragmentation will be significantly less than 50% of the total memory allocated.
- This model facilitates allocation of memory in contiguous
chunks of size equal to any power of two, up to some limit.
-
10.8.2 Slab Allocation
- The idea of the slab allocator is to use groups of pages
as an array of one specific kind of data structure: say
process descriptors, file objects, semaphores, and so on.
Each slab can be managed as with "fixed-sized partitioning."
This is very simple and there is 'no fragmentation' -- in that
the allocated objects are always the exact size required.
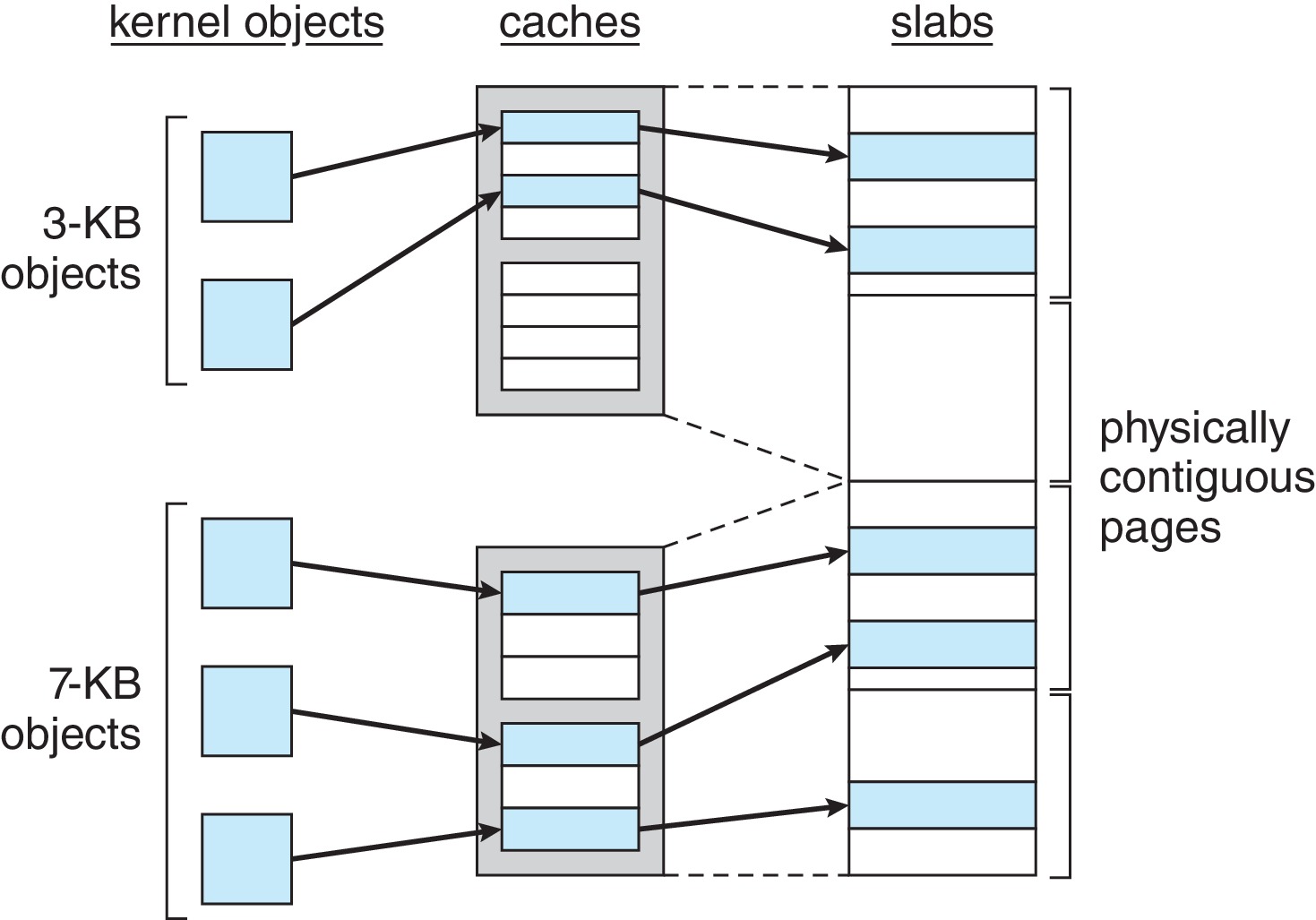
Figure 10.27: Slab allocation - The claim of 'no fragmentation' should be taken with a grain of salt. The unallocated portions of the slabs may be considered waste while they remain unused. Slab size is a multiple of the frame size.
- The idea of the slab allocator is to use groups of pages
as an array of one specific kind of data structure: say
process descriptors, file objects, semaphores, and so on.
Each slab can be managed as with "fixed-sized partitioning."
This is very simple and there is 'no fragmentation' -- in that
the allocated objects are always the exact size required.
-
10.9.1 Prepaging
- Under pure demand paging, we expect a large number of page
faults initially as a process begins execution, or as a process
which has been swapped out starts being swapped back in.
- It may help overall performance if the OS performs pre-paging.
- The idea of pre-paging is to load extra pages.
- When servicing a page fault, instead of only loading the page on which the
process faulted, load additional pages on which the process is
likely to fault soon.
- When swapping a process in, instead of demand paging, load the entire
working set.
- Clustering is a simple technique that can help. Each page is a member
of a cluster of, say 4-8 pages, and whenever we page in a member
of a cluster we always page in any other members of the cluster
that are not currently resident.
- Under pure demand paging, we expect a large number of page
faults initially as a process begins execution, or as a process
which has been swapped out starts being swapped back in.
-
10.9.2 Page Size
- Normally the architecture of the computer hardware determines
the page size (or some set of allowable page sizes.)
-
The trend in computer design has been to make page sizes larger
and larger over the past three decades or so.
Current page sizes range upwards of 4K bytes per page,
even on mobile systems.
- There is no agreement on what is the "best" page size.
- Arguments in support of BIG pages:
- When pages are bigger, page tables can be smaller.
- When pages are bigger it takes less time per byte to load pages
into primary memory.
- When pages are bigger we have fewer page faults.
- When pages are bigger we have more TLB cache hits.
- When pages are bigger, page tables can be smaller.
- Arguments in support of SMALL pages:
- The internal fragmentation caused when a process does not
end on a page-boundary will be less if page sizes are smaller
- With a smaller page size we have better resolution. Less unneeded material is paged into memory. Consequently there is less total I/O and less waste in the allocation of physical memory.
- The internal fragmentation caused when a process does not
end on a page-boundary will be less if page sizes are smaller
- Normally the architecture of the computer hardware determines
the page size (or some set of allowable page sizes.)
-
10.9.3 TLB Reach
- TLB hardware is expensive and it uses a lot of power.
- TLB reach is the number of addresses in memory that can be
accessed through the TLB. For standard paging, the formula
for TLB reach is
TLB reach == (number of TLB entries) * (page size).
- Greater TLB reach tends to increase the cache hit ratio, which
improves effective memory access time, turnaround time, and
throughput.
- To improve reach, one can make the TLB larger. However
increasing the page size will also improve TLB reach.
- Given a fixed average process size, internal fragmentation increases
with the page size - because the proportion of memory wasted by the
average process is roughly
page-size/2 ______________ process-size
- However, the formula above also indicates that,
for larger-than-average processes, we can use a larger
page size and yet not incur a proportion of wasted memory greater
than that of the average-sized process.
- Many modern systems are able to use more than one page size.
For example, Linux systems support 4KB and "huge"
pages. The ARMv8 architecture supports pages and regions of various
sizes.
- There are special bit fields in the TLB entries of these systems that indicate the use of a larger page or region.
- TLB hardware is expensive and it uses a lot of power.
-
10.9.4 Inverted Page Tables
- In a system with virtual memory and/or swapping, the OS must
maintain information to keep track of where all the non-resident
pages are located on secondary storage.
- If there are standard per-process page tables, the OS can use
the PTEs of non-resident pages to store (some of)
that information. Such PTEs don't contain a valid frame number.
Therefore the OS can use the space to store the on-disk-address
of the page.
- If the system uses an inverted page table for routine
logical-to-physical address translation, typically the OS must
maintain per-process external page tables in order to keep
track of that on-disk location information.
- Under these conditions, the per-process external page table is
needed only when the process gets a page-fault.
The external tables can be paged-out to swap space most of the time.
Therefore, through the use of an inverted page table in a system with virtual memory, it is possible to reduce the total amount of physical memory allocated to page tables.
- Bear in mind, however, that when a page-fault occurs, the OS may need to page in part of the external page table, and the page on which the process faulted.
- In a system with virtual memory and/or swapping, the OS must
maintain information to keep track of where all the non-resident
pages are located on secondary storage.
-
10.9.5 Program Structure
- The text cites an example where an array is laid out in
row-major form, each row on a separate page. A program that
initializes each array entry may incur many more page faults
if it accesses the array a column at at time instead of a row
at a time.
- This illustrates that
details of program layout and address-referencing patterns can affect
process performance in a system with virtual memory.
- Compilers and loaders can help optimize performance by making judicious choices about where parts of the program are positioned in the memory.
- The text cites an example where an array is laid out in
row-major form, each row on a separate page. A program that
initializes each array entry may incur many more page faults
if it accesses the array a column at at time instead of a row
at a time.
-
10.9.6 I/O Interlock and Page Locking
- Hardware may provide a lock bit for each frame. When the
lock bit is set it means that this frame should not be replaced.
-
It is useful to lock kernel pages; user process pages with pending I/O;
and pages newly loaded, but as yet unused.
- If I/O is pending on a page, and the page is replaced before the I/O
happens, the I/O will take place between the device
and a bad address.
- Commonly, all or a part of the OS kernel is locked into memory.
As an example of why this may be necessary, consider what might
happen if a page X of the kernel memory-management module was
not resident in memory. What would happen if a kernel thread
faulted on page X, and if X contains the code for handling
the page fault?
- The OS may lock a newly-replaced frame F to make sure that the process P that owns F is allowed to use F at least once. If F is not locked, the OS might select F as a victim for page replacement again before P has a chance to use F.
- Hardware may provide a lock bit for each frame. When the
lock bit is set it means that this frame should not be replaced.
-
10.10.1 Linux
- Linux uses demand paging and global page replacement.
- The page replacement algorithm is similar to the LRU-approximation
clock algorithm.
- Linux maintains separate lists for relatively active and relatively
inactive pages.
- Linux has a reaper process called kswapd that is triggered when
free memory is below a threshold. Kswapd selects pages from
the inactive list and transfers them to the free list.
- There's more detail about Linux in Chapter 20.
- Linux uses demand paging and global page replacement.
-
10.10.2 Windows
- On 32-bit processors, Windows 10 supports virtual address
spaces of up to 3 GB.
- On 64-bit systems, it supports a 128 TB virtual address
space.
- Windows 10 supports multiple features, such as shared libraries,
demand paging, copy-on-write, paging, and memory compression.
- Windows 10 uses demand paging with clustering - whole page
clusters are fetched together following a page fault.
- A process is assigned a working set minimum and maximum number
of frames, but these are not hard limits.
- Windows 10 implements a LRU-approximation clock algorithm
for page replacement.
- The replacement policy is a combination of global and local.
- If a process faults when below its maximum working set,
or when free memory is plentiful , the OS gives the process
a frame from the free list.
- On the other hand, if memory is below a threshold, and
if a process faults when it has the max number of frames in its
working set, then the OS performs a
local page replacement.
- Also, when free memory is below threshold, the OS will take
frames away from processes that have more than their
working set minimum, and put them on the free list.
- If necessary to replenish memory availability, Windows 10 will take frames away from processes that are at or below their working set minimums.
- On 32-bit processors, Windows 10 supports virtual address
spaces of up to 3 GB.
-
10.10.3 Solaris
- Solaris performs global replacement
- When a thread faults, Solaris always gives it a new frame.
Therefore Solaris gives very high priority to assuring that
free frames are always available.
- If free memory falls below the threshold lotsfree
(about 1/64th of physical memory) then the pageout process
(page demon) starts running a two-handed clock algorithm.
- The front hand 'forgives.' It clears the reference bit.
The back hand 'reaps.' It frees the frames that have
not been referenced, and writes them, if dirty.
- After the pageout process "frees" a frame from a victim, if
the victim faults on the missing page before the frame is
reassigned, the OS will reclaim the frame from the free
list and give it back to the victim.
- The scanrate (# pages scanned per second)
and handspread (# pages between hands) can vary.
- If free memory drops below a certain level, the OS initiates
swapping.
- The page-scanning algorithm skips over pages belonging to libraries being shared by several processes.
- Solaris performs global replacement